

Connecting HubSpot and Jira promises a huge efficiency boost, but a simple, thoughtless sync can open your business up to serious GDPR violations and shatter customer trust. A truly GDPR-compliant CRM sync isn’t just about linking two platforms; it’s a strategic necessity. Let’s dig into why treating data privacy as an afterthought is a critical mistake.
Why A GDPR-Compliant Sync Is Not Optional

On the surface, integrating powerful tools like HubSpot and Jira feels like a no-brainer for productivity. Your sales team gets a window into development progress, and engineering gets the real-world context behind customer issues. It sounds perfect.
However, this connection can quickly become a major liability without a meticulous focus on data privacy. The heart of the problem is the transfer of personal data between systems. A poorly configured sync that just dumps all contact information from HubSpot into Jira tickets is a recipe for violating fundamental GDPR principles.
The Risks Of A Non-Compliant Integration
Think about it: a “sync-it-all” approach directly torpedoes the principle of data minimization. This core tenet of GDPR mandates that you only process data that is adequate, relevant, and strictly necessary for your purpose.
Does your development team really need a customer’s full contact history and marketing engagement to fix a software bug? Almost certainly not. This kind of over-sharing creates needless risk. Every piece of personal data you move to a new system multiplies its exposure and the potential for a breach.
Key Takeaway: A GDPR-compliant CRM sync isn’t about just connecting two apps. It’s a deliberate, security-first process that respects data privacy at every step. This protects your customers and your business from significant legal and financial penalties.
Building A Foundation Of Trust
The stakes couldn’t be higher. Today, a staggering 92% of companies globally use CRMs to store customer information, making GDPR adherence a non-negotiable business function. This heavy reliance on customer data means that maintaining trust is everything. A privacy-first integration isn’t just a legal checkbox; it’s a powerful signal to customers that you value their data.
This table breaks down some core GDPR principles and how they apply directly to your HubSpot-Jira sync.
Key GDPR Principles for Your CRM Sync
| GDPR Principle | Impact on Your HubSpot-Jira Sync | Actionable Example |
|---|---|---|
| Data Minimization | Only sync the absolute minimum data required for the task. | Instead of syncing the entire HubSpot contact record, only pass the Jira user’s name and company to a bug report. Avoid syncing phone numbers or addresses. |
| Purpose Limitation | Data synced to Jira should only be used for the specified purpose (e.g., bug fixing, feature requests). | Ensure data from a support ticket isn’t used for marketing campaigns without separate, explicit consent. |
| Data Security | Both HubSpot and Jira, and the integration tool itself, must have strong security measures. | Use a reputable integration app with encrypted data transfer and robust access controls. Regularly audit who can see what data in both platforms. |
| Data Subject Rights | You must be able to honor user requests to access, rectify, or erase their data across both systems. | If a user requests data deletion in HubSpot, your process must ensure their associated data is also removed or anonymized in any linked Jira issues. |
Understanding these principles is the first step toward building a responsible integration.
To really nail this, you need a solid plan. Consulting an ultimate GDPR compliance checklist is a great starting point for covering all your bases. For those specifically focused on this connection, our HubSpot Jira integration guide offers the essential context you need to start correctly.
Ultimately, building your integration with privacy as a core requirement is the only sustainable way forward.
Getting HubSpot and Jira Ready for a Secure Sync

A solid, compliant integration doesn’t start the moment you connect the two platforms. The real work begins beforehand. This foundational prep is your best defense against accidental data leaks and compliance headaches, paving the way for a truly GDPR-compliant CRM sync.
The very first thing to tackle is a full data audit inside HubSpot. You need a crystal-clear picture of what personal data you’re holding, where it came from, and your legal reason for having it. This isn’t just a box-ticking exercise; it’s a legal necessity. You have to confirm your lawful basis for processing and sharing every single piece of data before it goes anywhere.
As you set up your sync environment, it’s also smart to bake in strong security from the ground up, pulling from actionable DevOps security best practices. This ensures the pipes the data flows through are just as secure as the data itself.
Auditing and Tagging Your Data in HubSpot
Before you even think about syncing a single contact, you need a consent-based tagging system. It sounds complicated, but it can be as simple as creating a custom property in HubSpot just for this.
For example, you could create a custom property called “Jira Sync Consent” with a dropdown menu. The options are straightforward:
- Granted: This person has given you the green light to use their data in Jira for support or development.
- Not Granted: This person has not given consent, and their data must stay put in HubSpot.
- Revoked: Consent was given previously but has since been withdrawn.
This single property acts as the gatekeeper for your entire integration. It gives you a clear audit trail and an automated way to control the data flow, making sure you only sync what you’re legally allowed to.
Pro Tip: Don’t just create the property and call it a day. Build a process around it. Your support forms, sales calls, and customer onboarding flows should all have a step to capture and update this consent status directly in HubSpot.
Doing this prep work transforms GDPR compliance from a painful, reactive cleanup job into a proactive, built-in part of how you operate.
Setting Up Jira for Secure Data Handling
Over on the Jira side, the goal is to create a controlled, walled-off garden where the synced data will live. Don’t just dump CRM data into your main, wide-open development projects. That’s asking for trouble. Instead, set up a dedicated Jira project specifically for issues coming from HubSpot.
Inside this project, you’ll create custom fields that will catch the data mapped from HubSpot. This is where you put the principle of data minimization into practice. Resist the urge to create a field for every possible HubSpot property. If your developers only need a company name and a link back to the HubSpot ticket to fix a bug, then those are the only two fields you should create.
Example Jira Custom Field Setup
| Field Name | Field Type | Purpose |
|---|---|---|
| HubSpot Contact ID | Text Field | A non-sensitive ID to link back to the full HubSpot record. |
| Customer Company Name | Text Field | Gives the dev team context without sharing personal contact info. |
| HubSpot Ticket URL | URL Field | Lets authorized users click back into HubSpot for more detail if needed. |
| Reported Priority | Select List | Syncs the ticket’s priority level to help guide development schedules. |
By carefully designing these custom fields, you control exactly what information even enters Jira. This structure means that even if project permissions are a bit broad, the amount of exposed personal data is minimal by design. You’re fulfilling a core GDPR requirement before the sync is even turned on and preventing sensitive data from ever showing up where it doesn’t belong.
Configuring Your Sync with Privacy by Design
Alright, with your platforms prepped, it’s time to actually build the connection. A word of warning: a standard “sync all” approach is a compliance disaster just waiting to happen. Instead, you need to build this integration with a privacy-by-design mindset from the very beginning. This means you’re building the sync around what’s absolutely necessary, not just what’s possible.
This approach completely flips the script. You stop asking, “How much can we sync?” and start asking, “What is the absolute minimum data we need to get the job done?” For instance, a simple but powerful technique is to create a sync rule based on explicit consent. You can set up the integration to only push a HubSpot contact to Jira if a custom property, like Jira_Sync_Consent, is marked as “True.” It’s a straightforward rule that acts as an incredibly effective, automated gatekeeper for GDPR compliance.
Building this secure bridge involves careful data mapping, setting up the sync securely, and then keeping a close eye on it to ensure ongoing compliance.
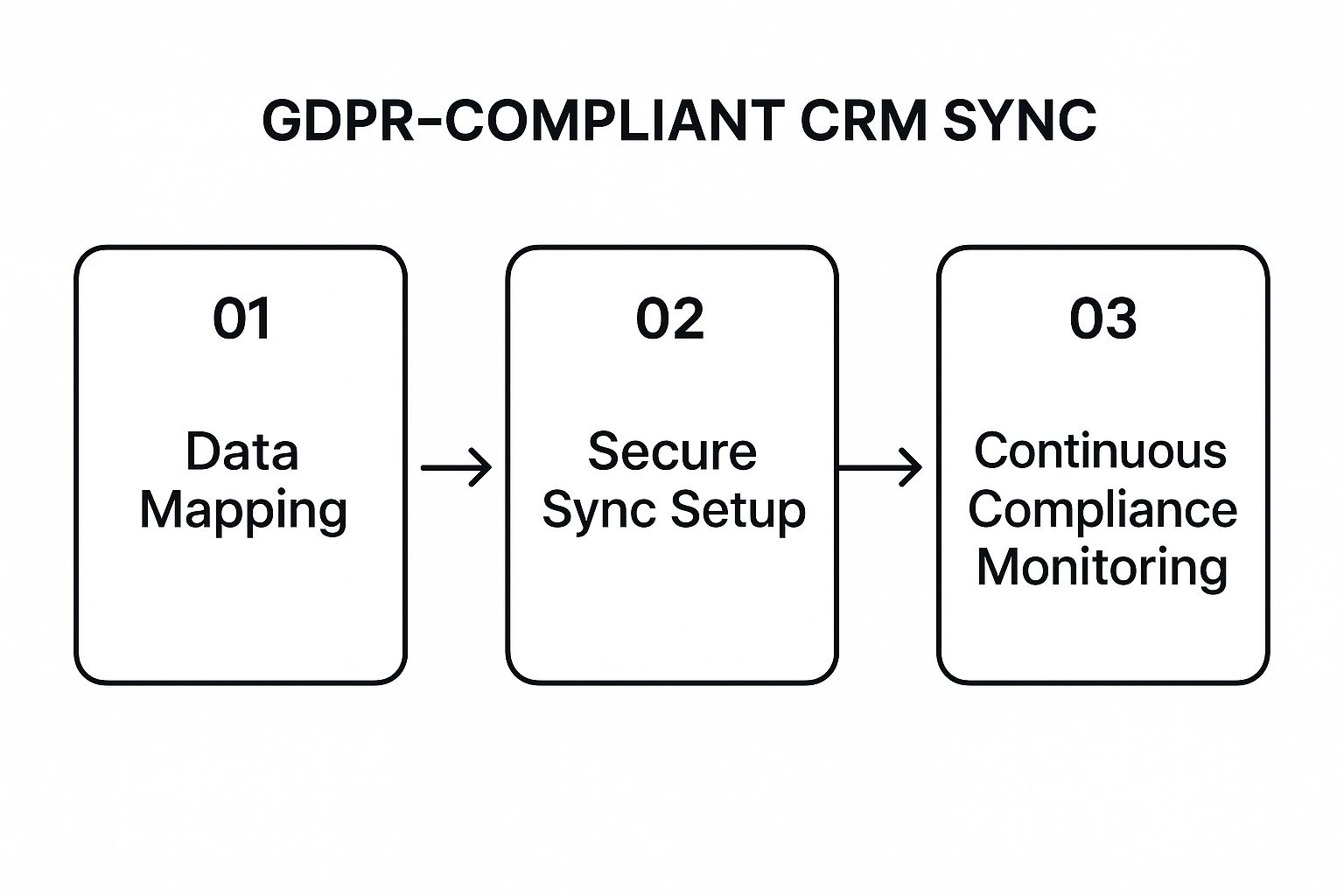
This visual really gets to the heart of it. A successful, secure sync isn’t a one-and-done setup; it’s a process with distinct stages that you need to get right.
A Deep Dive into Field Mapping
Field mapping is where the principle of data minimization really comes to life. This is where you tell your integration tool exactly which piece of HubSpot data should go into which Jira field. It’s your chance to be incredibly selective and stop sensitive personal data from ever landing in your development team’s workspace.
Let’s walk through a real-world scenario. A customer submits a bug report through a HubSpot form. Your dev team needs the technical context to fix it, but do they really need the customer’s personal phone number or direct email address? Probably not.
Your field mapping rules should reflect that reality. Here’s what that might look like:
- HubSpot Contact Name → Does NOT sync.
- HubSpot Contact Email → Does NOT sync.
- HubSpot Company Name → Jira “Customer Organization” Field. This gives context without sharing PII.
- HubSpot Ticket Subject → Jira Issue Summary. This is the core information your team needs.
- HubSpot Ticket Description → Jira Issue Description. This is where all the technical details of the bug live.
This granular level of control is the essence of a GDPR-compliant sync. By intentionally excluding sensitive fields, you give your teams the information they need to be effective while drastically cutting down your data privacy risk.
This selective syncing is a non-negotiable part of modern data protection. When you configure your sync, you’re essentially extending your CRM’s security principles beyond its own walls.
Automating with Consent-Based Triggers
To make this truly scalable, automation is your best friend. Building on that consent property we talked about, you can create workflows that handle the sync automatically. For example, when a new customer support ticket is created in HubSpot and the contact associated with it has the Jira_Sync_Consent property set to “True,” an automation rule can fire off and create a new Jira issue.
This setup achieves two critical things:
- It eliminates manual errors. No one on your team can accidentally sync a contact who hasn’t given their consent. The system just won’t allow it.
- It creates a full audit trail. The sync is directly tied to a recorded consent status, which makes proving compliance incredibly straightforward.
As you set up the sync, you should also look into technologies that employ essential cloud data loss prevention strategies to protect sensitive info from being exposed, whether by accident or by a malicious attack. It’s just another smart layer of security to add to your setup.
For those who want to get even more sophisticated with these connections, our guide on HubSpot and Jira automation covers more advanced techniques. By combining selective field mapping with consent-based automation, you build a bridge between your platforms that is both powerful and compliant.
Managing User Permissions and Access Controls
Getting a GDPR-compliant CRM sync right is about more than just which data fields you move back and forth. You also have to be incredibly deliberate about who can see that data once it lands in Jira. A sync isn’t really secure if sensitive customer info is suddenly an open book for your entire development team.
This is where the principle of least privilege isn’t just a suggestion—it’s your most critical tool.
The idea is straightforward: people should only have access to the data and tools they absolutely need to do their jobs. Nothing more. For our HubSpot-Jira sync, this means drawing a clear line in the sand. Technical folks get the issue details they need, but personal customer data stays locked down. This isn’t just a nice-to-have; it’s a non-negotiable for protecting personal information under GDPR.
Get this wrong, and you’re opening the door to internal data breaches. An employee might accidentally see information they’re not authorized to view, creating a compliance headache you really don’t need.
Setting Up Role-Based Access in HubSpot
Your first line of defense starts right inside HubSpot. Before any data even thinks about syncing, you need to lock down who can mess with the integration settings. HubSpot’s “Teams” and “User Roles” features are perfect for this.
A smart move is to create a dedicated team—call it something like “Integration Admins”—and give only them the keys to the kingdom. They’re the only ones who can change sync rules and field mappings. This simple step prevents a well-meaning but untrained team member from accidentally syncing a field full of PII and undoing all your careful compliance work.
Granular Controls with Jira Permission Schemes
Now for the real magic, which happens over in Jira’s permission schemes and project roles. This is where you build the digital fortress around your synced customer data. Don’t just dump all your developers into the project where HubSpot issues appear. Instead, create specific roles with different levels of access.
Let’s walk through a real-world scenario.
Scenario: A customer submits a ticket through HubSpot about a critical software bug. The ticket includes their name, email, and a detailed technical log file. Your job is to get the technical log to a developer without ever showing them the customer’s personal details.
Here’s how you’d set it up using two distinct roles in your Jira project’s permission scheme:
- Developer Role: This role can see and edit the standard Jira fields—summary, description, attachments, you name it. But, you explicitly block this role from seeing any custom fields where the HubSpot PII lives, like “Customer Email” or “Contact Phone.” They can’t see it, period.
- Support Lead Role: This role has a higher level of access. A support lead sees everything the developer can, plus they have permission to view the protected custom fields with the synced HubSpot data.
This setup is clean and effective. A developer can investigate the bug, check the logs, and fix the problem without ever touching personal data. If they hit a wall and need more context, they can ping a Support Lead, who is authorized to see the PII and can provide the necessary details.
This layered approach is a direct application of data minimization and security. It makes your sync truly robust and keeps the auditors happy.
Automating Compliance and Ongoing Maintenance

Getting your GDPR-compliant sync up and running is a huge win, but don’t pop the champagne just yet. Compliance isn’t a “set it and forget it” task. It’s a living process that needs regular attention. A perfectly compliant setup today can easily drift out of spec tomorrow as your team adds new data fields or your internal processes change.
This is where automation becomes your best friend, helping you maintain that integrity over the long haul.
A classic example is handling data subject requests, a core tenet of GDPR. Manually processing a “right to be forgotten” request across both HubSpot and Jira is not just slow—it’s a minefield of potential errors and compliance risks. A much smarter approach is to build an automated workflow.
Proactive Governance and Audits
Think about it: you can create a workflow where changing a contact’s status to “Erasure Request” in HubSpot kicks off an automatic process in Jira. This could trigger a script to anonymize personal data in the associated Jira tickets, swapping names and emails for placeholder text. The technical details remain for historical context, but the personal data vanishes.
This kind of automation ensures requests are handled quickly and consistently. But it’s not foolproof. You still need to run regular audits on your sync. These checks are absolutely critical to verify that your rules are firing as expected and that no stray personal data is slipping through the cracks.
Key Takeaway: Treat your GDPR-compliant sync like a garden. You can’t just plant it and walk away. Regular audits and proactive automation are the tools you use to keep it healthy and ensure your data handling stays compliant as your business evolves.
The Rise of AI in Compliance
The good news? Maintaining compliance is getting easier thanks to modern tools. The integration of artificial intelligence into GDPR-compliant CRM solutions is a game-changer. In fact, recent findings show that over 70% of CRM platforms are expected to pack in AI features like predictive analytics and automated compliance checks. This lets businesses shift from a reactive to a proactive stance on compliance.
AI can act as a constant watchdog for your data sync, flagging potential risks in your logic before they snowball into real problems. An AI tool might, for instance, detect a new, unmapped field in HubSpot that contains potentially sensitive data and immediately alert an admin. With more than 80% of businesses planning to invest in AI-powered CRM solutions, it’s clear this tech is becoming essential for both customer experience and regulatory peace of mind.
Ultimately, by combining smart automation, diligent auditing, and intelligent tools, ongoing maintenance shifts from a manual headache to a streamlined, reliable process. To dig deeper into this, you might find our guide on how to automate data entry processes effectively useful. This approach ensures your GDPR-compliant CRM sync stays robust and trustworthy for the long term.
Of course. Here is the rewritten section, designed to sound like it was written by an experienced human expert, following the provided style guide and examples.
Common Questions About Syncing HubSpot and Jira
When you start connecting a CRM like HubSpot to a development tool like Jira, a few key questions always pop up, especially when you’re trying to stay on the right side of GDPR. Let’s tackle the most common ones I hear from teams making this integration happen.
How Much Data Can We Actually Sync?
This is usually the first question people ask, and it gets right to the heart of GDPR. The better question isn’t “how much can we sync?” but rather, “what’s the absolute minimum data our developers need to do their job?” You have to start from a place of data minimization. It’s non-negotiable.
Think about it from a developer’s perspective. To fix a support ticket, they don’t need the customer’s entire life story from the CRM. What they typically need is pretty simple:
- A non-personal ID to link the Jira issue back to HubSpot.
- The customer’s company name for context.
- The technical details of the bug or problem.
Anything more than that, like a phone number or a direct email address, is usually just noise for the engineering team. Make a conscious decision to exclude those fields during your initial setup.
The goal is to give your teams just enough information to be effective, not to turn Jira into a carbon copy of your CRM. This approach massively reduces your compliance risk.
Do We Really Need Consent for Every Single Sync?
If you’re syncing personal data, then yes, you absolutely need a clear, lawful basis for processing it. Relying on explicit consent is always the most transparent and defensible route.
You can’t just assume that because a customer gave you their data for marketing emails, it’s a free pass to send that same data over to your development team’s bug-tracking system. These are entirely different purposes.
This is exactly why we recommend creating a dedicated consent property right inside HubSpot—something like a checkbox for “Jira_Sync_Consent.” It creates an undeniable record that the person has specifically agreed to this use of their data. Without that clear signal, you’re operating in a very risky gray area that could easily lead to serious GDPR trouble.
What Happens When a User Asks to Be Forgotten?
A “Right to be Forgotten” request isn’t just for one system; it applies everywhere you store that person’s data. If you’ve set up a GDPR-compliant CRM sync, you must have a solid process for this. It’s a critical test of your compliance.
When a contact is deleted or anonymized in HubSpot, that action has to kick off a corresponding process in Jira. This usually looks like:
- Your integration automatically finds all Jira issues linked to that specific HubSpot contact.
- A script then runs to anonymize the personal data within those Jira issues.
This has to be automated. Trying to manually hunt down every associated Jira ticket is a recipe for disaster—it’s slow, and human error is practically guaranteed. When it comes to data subject rights, that’s a risk you just can’t afford to take.
Break down data silos and empower your teams with resolution Reichert Network Solutions GmbH. Our HubSpot for Jira app creates a seamless, real-time connection between your CRM and development workflows, ensuring everyone has the context they need without leaving their platform. Learn more and see how it works.
