

Unifying Your Data Universe: HubSpot and Jira in Perfect Harmony
Do your HubSpot CRM and Jira instances feel like separate planets? Misaligned data creates friction for revenue, support, and product teams. This listicle reveals data integration best practices, demonstrating how a unified view of customer and project data fuels efficiency and growth. Learn how to streamline workflows, improve data accuracy, and unlock valuable insights using the HubSpot for Jira app. Discover practical tips for data quality management, API integration, real-time syncing, and more. Stop juggling disparate systems and start maximizing the value of your data.
1. Data Quality Management and Validation
Data quality management and validation is the cornerstone of any successful data integration strategy. It encompasses a comprehensive approach to ensuring data accuracy, completeness, consistency, and reliability throughout the integration process. This crucial practice involves implementing validation rules, data profiling, cleansing processes, and continuous monitoring to maintain high data quality standards across all integrated systems. For teams working within HubSpot and Jira, maintaining data integrity is paramount for efficient workflows, reliable reporting, and informed decision-making. Without accurate data flowing between these systems, revenue operations, support, and product teams can face significant challenges, including inaccurate reporting, flawed analysis, and ultimately, missed opportunities.

Alt text: Diagram illustrating data quality management process including profiling, cleansing, matching, and monitoring.
This best practice deserves its place on the list because it directly impacts the usability and trustworthiness of your integrated data. Inaccurate or incomplete data can lead to faulty analytics, flawed decision-making, and operational inefficiencies. For example, inaccurate lead information in HubSpot, if synced with Jira, can lead to development teams working on features for the wrong target audience. Conversely, inaccurate bug reports originating in Jira, if not properly cleansed and validated before syncing with HubSpot, can misinform customer service representatives and lead to customer frustration. Effective data quality management mitigates these risks.
Data quality management and validation incorporates several key features:
- Automated data profiling and quality assessment: Tools automatically analyze data sources to identify patterns, anomalies, and potential data quality issues. This helps understand the current state of your data.
- Real-time validation rules and constraints: Pre-defined rules ensure data conforms to specific criteria before it’s integrated. For example, enforcing correct formatting for phone numbers or email addresses.
- Data cleansing and standardization processes: These processes address inconsistencies and errors in data, such as deduplication, address correction, and format standardization.
- Quality metrics and KPI tracking: Monitor data quality over time with metrics like accuracy, completeness, and consistency. These KPIs can be tracked on dashboards and reports, providing insights into trends and areas needing improvement.
- Exception handling and error reporting: Mechanisms are put in place to identify and manage data quality exceptions, ensuring issues are flagged and addressed promptly.
- Master data management capabilities: Establishing a single source of truth for critical data elements ensures consistency across systems.
Implementing robust data quality management offers several advantages:
Pros:
- Improved decision-making through reliable data: Accurate data leads to more informed business decisions.
- Reduced operational costs from data errors: Fewer errors mean less time spent on fixing issues and rework.
- Enhanced customer experience and trust: Accurate data leads to better personalization and smoother customer interactions.
- Compliance with regulatory requirements: Data quality management helps meet industry regulations regarding data accuracy and security.
- Better analytics and reporting accuracy: Data quality directly impacts the reliability of reports and analytics.
Cons:
- High initial implementation costs: Implementing robust data quality management tools and processes can be expensive.
- Requires significant time investment: Setting up and configuring data quality rules and processes requires dedicated time and resources.
- May slow down data processing speeds: Real-time validation checks can add slight latency to data integration processes.
- Needs ongoing maintenance and updates: Data quality rules and processes require continuous monitoring, refinement, and updates as business needs evolve.
- Can be complex to implement across multiple systems: Integrating data quality management across diverse systems requires careful planning and execution.
Several organizations have successfully implemented data quality initiatives: Netflix uses data quality checks to ensure accurate content recommendations, while Bank of America implements comprehensive data validation for regulatory compliance. Walmart leverages real-time inventory data quality management across its global operations. These examples showcase the wide applicability and significant benefits of robust data quality management.
Tips for Implementing Data Quality Management:
- Start with critical business data first: Focus initial efforts on the data elements that have the biggest impact on business operations.
- Implement automated quality checks at data entry points: Prevent bad data from entering the system in the first place.
- Establish clear data ownership and accountability: Define who is responsible for maintaining data quality for specific data sets.
- Use data quality dashboards for visibility: Track key metrics and identify areas needing improvement.
- Create standardized data definitions across teams: Ensure everyone uses the same terminology and definitions for data elements.
- Regularly audit and update validation rules: As business needs change, update validation rules to ensure data accuracy.
Popular tools for data quality management include IBM InfoSphere, Informatica Data Quality, Talend Data Quality, and Microsoft Data Quality Services. Learn more about Data Quality Management and Validation. By prioritizing data quality management and validation, organizations can ensure that their data integration efforts deliver accurate, reliable, and actionable insights. This, in turn, empowers data analysts and reporting specialists, sales and marketing teams using HubSpot, customer support agents, product and project management teams, and Jira administrators to make informed decisions and drive business success.
2. Incremental Data Loading and Change Data Capture (CDC)
Incremental data loading and Change Data Capture (CDC) are essential data integration best practices for modern businesses relying on real-time data synchronization. Instead of transferring entire datasets with each integration cycle, which can be resource-intensive and time-consuming, this approach focuses on capturing and processing only the changes (inserts, updates, and deletes) made since the last synchronization. This efficiency boost allows for near real-time data synchronization across different systems, a crucial advantage in today’s fast-paced business environment. This approach is particularly beneficial for teams using platforms like HubSpot and Jira, where keeping data aligned is crucial for efficient collaboration and reporting. By only syncing changed data, teams avoid unnecessary load on both platforms and ensure that everyone works with the most current information.
CDC operates by meticulously tracking changes within the source system. This tracking can be achieved through various methods such as log-based CDC, where database transaction logs are monitored, or trigger-based CDC, where triggers are set up to capture changes as they occur. Other mechanisms include timestamp-based tracking, which identifies changes based on modification times, and version-based tracking, which assigns versions to data records. This captured change data, often referred to as a delta, is then processed and applied to the target system, ensuring consistency across platforms. Features like conflict resolution mechanisms, rollback options, and robust change tracking are incorporated to maintain data integrity throughout the process.
The benefits of incorporating incremental loading and CDC into your data integration best practices are substantial. It significantly reduces processing time and costs, lowers network bandwidth requirements, and minimizes the impact on source systems. This efficiency translates into improved scalability for large datasets, reduced storage requirements, and the ability to perform real-time analytics and reporting, empowering businesses to make data-driven decisions quickly. For instance, imagine your sales and marketing teams using HubSpot and your development team using Jira. With CDC, updates to a contact in HubSpot, such as a change in lifecycle stage, can be instantly reflected in Jira, providing the development team with real-time context for their work.
However, implementing CDC isn’t without its challenges. It requires a more complex setup and ongoing maintenance compared to full data loads. Robust change tracking mechanisms are essential to ensure no changes are missed. Potential data consistency issues need careful consideration, and appropriate conflict resolution strategies must be put in place. Furthermore, the initial setup can be time-intensive, and successful implementation relies on the capabilities of the source system.
Several companies have successfully leveraged incremental loading and CDC to achieve real-time data synchronization. LinkedIn, for example, uses CDC to propagate member profile updates across its various platforms, ensuring data consistency and a seamless user experience. Similarly, Uber implements incremental loading to synchronize ride and driver data, enabling real-time tracking and analysis of its operations. Salesforce, another example, utilizes real-time data replication via CDC for seamless CRM integrations.
The following infographic visualizes the three key steps in the incremental data loading process.
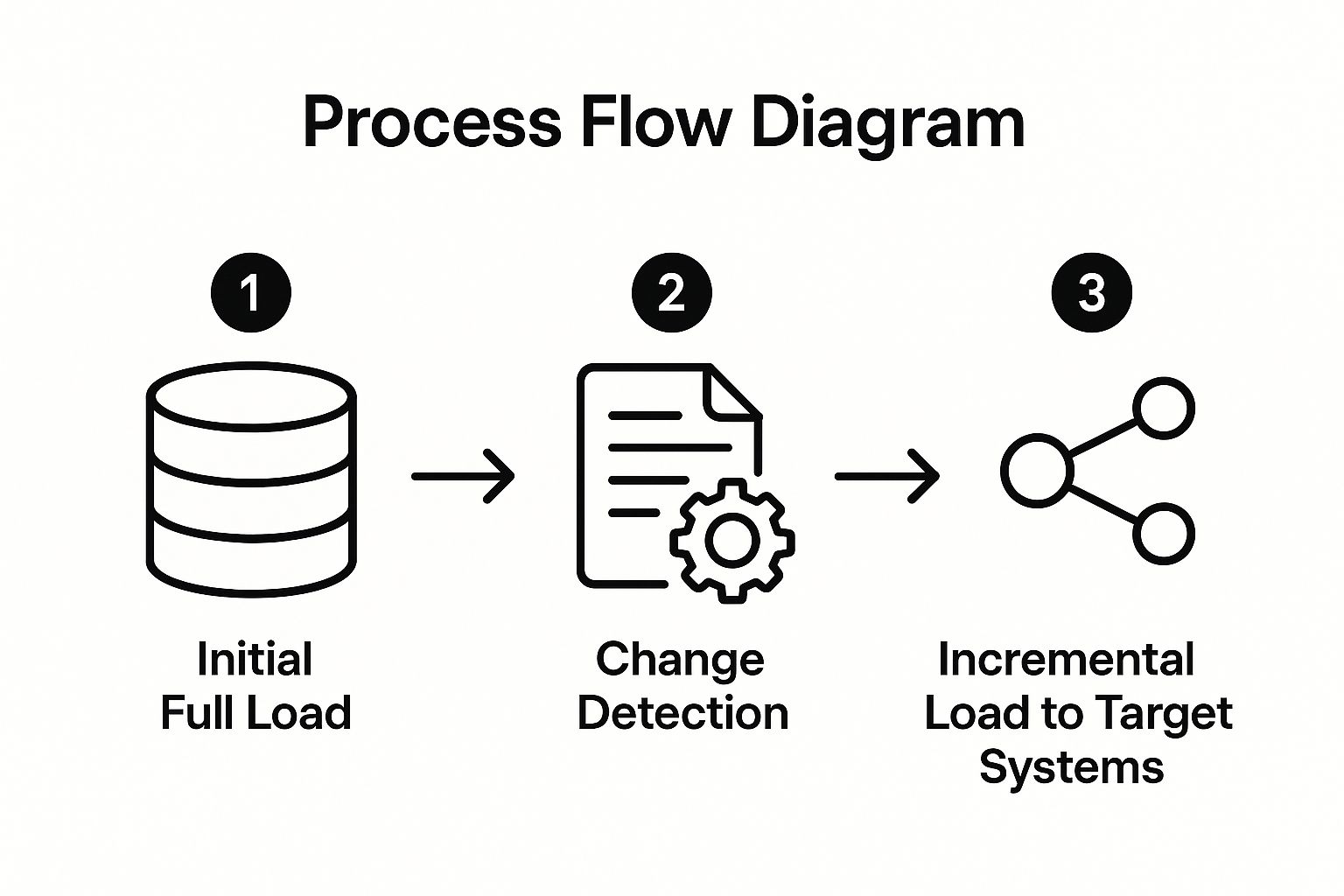
The infographic illustrates the sequential process: starting with an initial full load to establish a baseline, followed by continuous change detection, and finally, the incremental loading of those changes to the target system. This iterative process ensures only the necessary data is transferred, optimizing efficiency.
To successfully implement incremental loading and CDC as part of your data integration best practices, consider the following tips: choose the appropriate CDC method based on your source system’s capabilities, develop and implement robust conflict resolution strategies, meticulously monitor CDC lag and other performance metrics, thoroughly test the system with a range of change scenarios, plan for both the initial full load and ongoing incremental loads, and ensure clear documentation of your change tracking methodology. By following these data integration best practices and understanding the intricacies of incremental loading and CDC, you can achieve efficient, near real-time data synchronization, paving the way for streamlined workflows and informed decision-making. Tools like Apache Kafka Connect, Debezium, AWS Database Migration Service, Oracle GoldenGate, and Microsoft SQL Server CDC offer robust features to support your CDC implementation. By utilizing these tools and adhering to the recommended practices, you can significantly optimize your data integration processes and enhance your overall data management strategy.
3. API-First Integration Architecture
API-first integration architecture is a critical data integration best practice that prioritizes Application Programming Interfaces (APIs) as the primary method for data exchange and system communication. Instead of relying on point-to-point connections or complex middleware, an API-first approach emphasizes designing well-documented, versioned, and secure APIs. These APIs act as intermediaries, enabling seamless communication between different applications, microservices, and external systems. This approach promotes loose coupling, meaning systems are less dependent on each other’s internal workings, and high reusability, allowing the same API to serve multiple purposes and integrations. For teams working across HubSpot and Jira, adopting an API-first approach unlocks significant benefits for data integration best practices by streamlining workflows and enhancing data visibility.

Alt text: Diagram illustrating API-First Architecture with various applications connecting to a central API Gateway.
This method works by exposing specific functionalities and data of a system through well-defined APIs. When another system needs to interact with this data or functionality, it does so through the API, rather than directly accessing the underlying database or system. This allows for greater flexibility and control over data access and ensures changes in one system don’t necessitate significant rework in others. For example, Jira administrators can leverage Jira’s REST API to integrate with HubSpot, enabling automated ticket creation based on HubSpot deal stages. Similarly, DevOps managers can use APIs to automate code deployments triggered by Jira issue updates. Sales and marketing teams using HubSpot benefit from API-driven data synchronization between HubSpot and other marketing automation tools. Customer support agents can utilize APIs to integrate support ticketing systems with Jira, ensuring seamless issue tracking and resolution. Product and project management teams can use APIs to connect Jira with product roadmap tools, providing real-time project status updates. Finally, data analysts and reporting specialists can leverage APIs to extract data from various sources and consolidate it for comprehensive analysis.
Several successful examples highlight the power of API-first integration. Stripe’s comprehensive payment API ecosystem allows businesses to easily integrate payment processing into their applications. Twilio’s communication APIs enable global integration of messaging and voice services. Shopify’s robust REST and GraphQL APIs provide a foundation for e-commerce platform extensions and customizations. These examples demonstrate the scalability and flexibility of API-first architecture.
Why choose API-first integration?
This approach deserves a prominent place in the list of data integration best practices due to its significant advantages:
- High Flexibility and Reusability: APIs can be reused across multiple integrations, reducing development time and effort.
- Easier Maintenance and Updates: Changes to underlying systems can be made without impacting integrated applications as long as the API interface remains consistent.
- Better Scalability and Performance: APIs can handle high volumes of requests and can be easily scaled to accommodate growing needs.
- Enhanced Security through Controlled Access: API gateways and authentication mechanisms ensure only authorized systems and users can access data.
- Simplified Integration with Third-Party Systems: APIs provide a standardized way to connect with external systems, reducing integration complexity.
- Supports Microservices Architecture: API-first architecture is essential for building and managing complex microservices ecosystems.
However, there are some drawbacks to consider:
- Requires Significant Upfront Design Effort: Careful planning and design are crucial for creating effective and reusable APIs.
- Network Dependency and Latency Concerns: API calls rely on network communication, introducing potential latency and dependency on network availability.
- Potential Single Points of Failure: API gateways can become single points of failure if not properly designed and managed.
- Complexity in Managing Multiple API Versions: Maintaining backward compatibility across different API versions can be challenging.
- Security Vulnerabilities if Not Properly Implemented: Improperly secured APIs can expose sensitive data to unauthorized access.
Actionable Tips for Implementing API-First Integration:
- Design APIs with clear, consistent naming conventions: This improves API usability and reduces integration friction.
- Implement comprehensive error handling and status codes: Provide informative error messages to help developers troubleshoot integration issues.
- Use API versioning strategies from the beginning: Plan for future changes and maintain backward compatibility with older versions.
- Provide interactive documentation and SDKs: Make it easy for developers to understand and use your APIs.
- Monitor API performance and usage metrics: Track API usage and identify potential bottlenecks or performance issues.
- Implement proper authentication and rate limiting: Secure your APIs and prevent abuse by implementing appropriate security measures.
By embracing API-first integration architecture, organizations can achieve a more agile, scalable, and maintainable approach to data integration. This best practice is especially crucial for organizations using HubSpot and Jira, enabling them to streamline workflows, improve data visibility, and achieve greater operational efficiency. Consider incorporating these data integration best practices into your overall strategy for optimal results.
4. Real-Time Streaming Data Integration
Real-time streaming data integration is a crucial component of modern data integration best practices. Unlike traditional batch processing, which moves data in large chunks at scheduled intervals, this approach processes and moves data continuously as it’s generated. This allows businesses to gain immediate insights and take action in real-time, a necessity in today’s fast-paced digital landscape. This practice is particularly valuable for time-sensitive applications where up-to-the-second data is essential for making informed decisions. For teams working across HubSpot and Jira, real-time data synchronization can significantly improve collaboration and efficiency by ensuring everyone has access to the most current information.

Real-time streaming data integration leverages streaming technologies like Apache Kafka and Amazon Kinesis to handle high-velocity data flows. These technologies provide the low-latency processing required for applications such as fraud detection, IoT monitoring, and real-time analytics. Think of it as a constant flow of information, rather than a periodic snapshot. This continuous data stream enables a more dynamic and responsive approach to data management, empowering businesses to react quickly to changing conditions and capitalize on opportunities as they arise. For Jira administrators and DevOps managers tracking system performance, this means immediate alerts and the ability to address issues proactively. Sales and marketing teams using HubSpot can personalize customer interactions based on real-time behavior and trigger automated campaigns based on specific events.
Features of Real-Time Streaming Data Integration:
- Event-driven data processing: Data is processed as soon as it’s generated, triggered by specific events.
- Low-latency data streaming: Data is moved and processed with minimal delay, providing near-instantaneous insights.
- Scalable message queuing systems: Handles large volumes of incoming data efficiently and reliably.
- Stream processing and analytics: Enables real-time analysis of data streams for immediate insights.
- Fault tolerance and data durability: Ensures data integrity and availability even in case of system failures.
- Schema evolution and compatibility: Adapts to changes in data structure without disrupting the data pipeline.
Benefits and Drawbacks:
Real-time streaming data integration, while powerful, comes with its own set of advantages and disadvantages. Understanding these trade-offs is essential for determining if this approach aligns with your specific needs and resources.
Pros:
- Immediate data availability and insights: Enables faster decision-making and proactive responses.
- Better customer experience through real-time responses: Personalized and timely interactions enhance customer satisfaction.
- Early detection of issues and anomalies: Proactive identification of problems minimizes impact and downtime.
- Competitive advantage through faster decision-making: React to market changes and opportunities more quickly than competitors.
- Reduced data staleness: Ensures that decisions are based on the most current information.
- Enables event-driven architectures: Facilitates building responsive and scalable applications.
Cons:
- Higher infrastructure and operational costs: Implementing and maintaining streaming systems can be expensive.
- Complex system design and maintenance: Requires specialized skills and expertise.
- Potential for data duplication or loss: Requires careful design to ensure data integrity.
- Requires specialized skills and expertise: Finding and retaining skilled professionals can be challenging.
- Challenging debugging and troubleshooting: Real-time systems can be complex to debug and troubleshoot.
- Network and system reliability dependencies: Performance is heavily reliant on network and system stability.
Examples of Successful Implementation:
Several organizations have successfully implemented real-time streaming data integration to gain a competitive edge:
- Netflix: Uses real-time streaming to update its recommendation engine, providing personalized suggestions based on current viewing trends.
- PayPal: Employs streaming data for fraud detection, identifying and preventing fraudulent transactions in real time.
- Uber: Leverages real-time demand data to adjust surge pricing dynamically.
- Twitter: Processes tweets in real time to identify trending topics and provide users with up-to-the-minute information.
Tips for Implementing Real-Time Streaming Data Integration:
- Choose appropriate streaming technology: Select a technology that aligns with your specific needs and resources.
- Design for fault tolerance and data recovery: Implement mechanisms to ensure data integrity and availability in case of system failures.
- Implement proper monitoring and alerting: Set up real-time monitoring to identify and address issues proactively.
- Plan for schema evolution and backward compatibility: Ensure that your system can adapt to changes in data structure without disrupting the data pipeline.
- Consider data ordering and exactly-once processing: Implement strategies to ensure data consistency and avoid duplication.
- Test thoroughly under various load conditions: Validate system performance and stability under different scenarios.
Popularized By:
Several platforms and technologies facilitate real-time streaming data integration, including Apache Kafka, Apache Storm, Apache Flink, Amazon Kinesis, Google Cloud Pub/Sub, and Confluent Platform.
By carefully considering the features, benefits, and challenges of real-time streaming data integration, businesses can determine if this approach is the right fit for their data integration best practices. When implemented correctly, it can unlock valuable insights, improve operational efficiency, and provide a significant competitive advantage. This is particularly relevant for those leveraging the HubSpot for Jira integration, as real-time data synchronization can significantly improve cross-functional alignment and drive better outcomes. Consider exploring the Atlassian Marketplace for more tools and resources that can support your data integration strategy.
5. Data Lineage and Metadata Management
Data lineage and metadata management form a critical pillar of data integration best practices. This practice involves tracking and documenting the complete lifecycle of data—from its origin, through various transformations, to its final destination. It also includes maintaining comprehensive metadata, which describes the characteristics of your data, including its source, transformations applied, dependencies, and usage patterns. This detailed record provides transparency, enhances compliance, and promotes effective data governance throughout the entire integration process. Implementing robust data lineage and metadata management is essential for organizations aiming to leverage the full potential of their data.
Understanding data lineage and metadata management is crucial for any data integration project, especially in the evolving Web3 landscape. Keeping track of data origin, transformations, and overall quality ensures trust and reliability. For deeper insights into this evolving space, explore current Web3 statistics.
Imagine being able to trace the exact path of a critical piece of data, understanding where it came from, how it was modified, and who accessed it. This is the power of data lineage. Coupled with detailed metadata, this empowers organizations with a deep understanding of their data assets. This deep understanding is invaluable for data integration best practices, enabling teams to troubleshoot issues faster, ensure data quality, and comply with regulations.
Several key features make data lineage and metadata management truly effective:
- End-to-end data flow visualization: Provides a clear visual representation of the data journey.
- Automated lineage discovery and tracking: Reduces manual effort and ensures accuracy.
- Impact analysis and dependency mapping: Allows for better understanding of potential consequences of changes.
- Business and technical metadata management: Caters to both technical and business users.
- Data catalog and discovery capabilities: Makes it easier to find and reuse existing data.
- Compliance and audit trail documentation: Simplifies compliance reporting and audits.
The advantages of adopting these practices are numerous:
- Enhanced data governance and compliance: Ensures data is handled responsibly and meets regulatory requirements.
- Faster troubleshooting and root cause analysis: Quickly identifies the source of data errors and inconsistencies.
- Improved data quality and trust: Builds confidence in the reliability and accuracy of data.
- Better impact assessment for changes: Predicts the impact of changes to data pipelines and systems.
- Simplified regulatory reporting: Streamlines the process of generating reports for regulatory bodies.
- Increased data discoverability and reuse: Facilitates the identification and reuse of valuable data assets.
However, implementing data lineage and metadata management also presents some challenges:
- Requires significant initial setup and configuration: Implementing these systems can be time-consuming and resource-intensive.
- Ongoing maintenance overhead: Maintaining accurate and up-to-date lineage information requires continuous effort.
- Can become complex in large environments: Tracking data across complex systems can be challenging.
- May impact system performance if not optimized: Lineage tracking can introduce performance overhead if not implemented carefully.
- Requires cultural change and user adoption: Successful implementation requires buy-in from all stakeholders.
Several successful examples demonstrate the value of these practices:
- JPMorgan Chase: Utilizes comprehensive data lineage for regulatory compliance.
- Airbnb: Leverages metadata management for data discovery and governance.
- Capital One: Implemented data lineage for risk management.
- ING Bank: Employs end-to-end data tracking for GDPR compliance.
To successfully implement data lineage and metadata management, consider the following tips:
- Start with critical business processes and high-value data: Focus initial efforts on the most important data assets.
- Automate lineage capture wherever possible: Reduce manual effort and improve accuracy.
- Establish clear metadata standards and definitions: Ensure consistency and clarity in metadata management.
- Integrate lineage tools with existing data platforms: Streamline workflows and avoid data silos.
- Train users on data catalog usage and benefits: Encourage user adoption and maximize value.
- Regularly review and update lineage information: Maintain the accuracy and relevance of lineage data.
Popular tools for data lineage and metadata management include Apache Atlas, Collibra Data Governance, Informatica Axon, Alation Data Catalog, and DataHub by LinkedIn. These platforms offer a range of features and functionalities to help organizations effectively manage their data lineage and metadata. By carefully considering these best practices and selecting the right tools, organizations can build a robust foundation for data governance and unlock the full potential of their data assets. This is especially important for teams using both HubSpot and Jira, allowing them to ensure consistent data quality and improve efficiency by eliminating manual data entry and reducing errors. By adhering to data integration best practices, including data lineage and metadata management, businesses can achieve greater agility and make data-driven decisions with confidence.
6. Error Handling and Data Recovery Strategies
Robust error handling and data recovery are crucial for any successful data integration project. This aspect of data integration best practices ensures business continuity and maintains data integrity, especially vital for teams relying on the seamless flow of information between systems like HubSpot and Jira. Without a comprehensive framework for managing integration failures, your business risks data loss, corrupted records, and system downtime, all of which can negatively impact customer experience, reporting accuracy, and overall productivity. This practice involves implementing proactive error detection, graceful handling mechanisms, and robust recovery procedures to address integration failures, data corruption, and system outages.
Imagine this: your sales team in HubSpot relies on real-time updates from Jira regarding bug fixes impacting key clients. A temporary network glitch causes the integration to fail, leading to outdated information in HubSpot and frustrated sales representatives who unknowingly promise resolved issues. A robust error handling system would detect this failure, perhaps retry the connection, and ultimately alert the relevant teams while storing the failed update attempt for later processing. This proactive approach minimizes disruption and ensures data consistency.
Features of a Robust Error Handling System:
- Automated error detection and classification: The system automatically identifies errors and categorizes them based on type and severity. This allows for specific responses to different error scenarios.
- Retry mechanisms with exponential backoff: Transient errors, like temporary network issues, are handled through automatic retries. Exponential backoff prevents overwhelming the system by increasing the time between retry attempts.
- Dead letter queues for failed messages: Messages that repeatedly fail are moved to a dedicated queue (a ‘dead letter queue’) for manual inspection and resolution. This prevents clogging the main integration pipeline.
- Circuit breaker patterns for system protection: When repeated failures indicate a larger systemic issue, a circuit breaker temporarily halts the integration flow to prevent cascading failures and protect downstream systems. This is particularly important in microservice architectures.
- Automated and manual recovery procedures: Automated procedures attempt to resolve common errors and restore the integration flow. Manual procedures provide options for intervention when automated processes are insufficient.
- Comprehensive logging and alerting systems: Detailed logs track errors and their resolution. Alerts notify administrators of critical failures requiring immediate attention. This allows for proactive issue identification and resolution.
Pros of Implementing Robust Error Handling:
- Improved system reliability and uptime: By addressing errors proactively, the system remains operational and available to users, minimizing downtime.
- Faster recovery from failures: Automated recovery procedures and clear documentation facilitate swift restoration of the integration flow after an outage.
- Reduced data loss and corruption: Mechanisms like dead letter queues and retry logic help preserve data integrity by ensuring that messages are not lost during failures.
- Better user experience during outages: Graceful degradation and proactive communication can minimize the impact of failures on end-users.
- Reduced manual intervention requirements: Automated processes handle many common errors, freeing up administrators to focus on more complex issues.
Cons to Consider:
- Increased system complexity: Implementing these features adds layers to the integration architecture, requiring careful design and implementation.
- Additional infrastructure and storage costs: Dead letter queues, logging systems, and monitoring tools require additional infrastructure and storage capacity.
- Potential for cascading failures if not designed properly: Improperly implemented error handling can exacerbate failures, leading to cascading effects across the system.
- Requires thorough testing of failure scenarios: Rigorous testing is essential to ensure the effectiveness of the error handling system.
Examples of Successful Implementations:
- Netflix (Hystrix): Pioneered the use of circuit breakers to improve the resilience of its microservice architecture.
- Google (Site Reliability Engineering): Employs comprehensive error handling and recovery practices to ensure the availability of services like Gmail.
- Amazon (AWS Well-Architected Framework): Provides guidance on building resilient and fault-tolerant systems on AWS, including best practices for error handling.
- Uber: Leverages resilience engineering practices, including chaos engineering, to test and improve the robustness of its systems.
Actionable Tips for Implementation:
- Implement different strategies for different types of errors: Distinguish between transient and persistent errors and implement appropriate handling mechanisms.
- Use exponential backoff to avoid overwhelming systems: Prevent cascading failures by increasing the time between retry attempts.
- Set up comprehensive monitoring and alerting: Gain visibility into system health and receive timely notifications of critical errors.
- Test failure scenarios regularly through chaos engineering: Proactively inject failures into the system to identify weaknesses and improve resilience.
- Document recovery procedures clearly: Ensure that teams can quickly restore the integration flow in case of an outage.
- Implement graceful degradation for non-critical features: Prioritize critical functionality during outages to minimize disruptions for users.
By incorporating these data integration best practices, particularly regarding error handling and recovery, organizations using platforms like HubSpot and Jira can ensure data integrity, system stability, and a seamless flow of information, ultimately contributing to improved productivity and better business outcomes. This is especially crucial for rev-ops leaders, support managers, and product teams who rely on accurate and timely data for decision-making and customer interactions. Consider solutions like the HubSpot for Jira app, available on the Atlassian Marketplace, to facilitate and enhance these best practices within your organization.
7. Data Security and Privacy Controls
Data security and privacy controls are paramount in any data integration best practice. This critical component ensures that sensitive information remains protected throughout the entire integration process, encompassing everything from transit and storage to processing and access. By implementing a robust security framework, organizations can mitigate risks, maintain compliance, and foster trust. This is particularly crucial for teams using platforms like HubSpot and Jira, where customer data, project details, and other sensitive information are constantly being exchanged. If you’re looking to improve your data integration best practices, security should be a top priority.
A comprehensive security framework typically includes several key features:
- End-to-end encryption: This ensures data is unreadable both while being transferred (in transit) and while stored (at rest). This is essential for protecting against unauthorized access, even if a breach occurs.
- Role-based access control (RBAC) and authentication: RBAC allows granular control over who can access what data, based on their role within the organization. Strong authentication mechanisms, like multi-factor authentication (MFA), further bolster security by verifying user identities.
- Data masking and anonymization techniques: These techniques protect sensitive data by replacing or removing identifying information while preserving the data’s utility for analysis and business operations.
- Audit logging and compliance monitoring: Detailed audit logs provide a record of all data access and modifications, enabling organizations to track activity, identify potential security breaches, and demonstrate compliance with regulations.
- Privacy-preserving data processing methods: Techniques like differential privacy allow for data analysis while adding noise to individual data points, making it difficult to identify individuals while still extracting valuable insights.
- Secure key management and rotation: This practice ensures that encryption keys are securely stored and regularly rotated, reducing the risk of compromise.
Implementing these security measures offers significant advantages:
- Protection against data breaches and cyberattacks: A strong security framework acts as a deterrent and minimizes the impact of potential security incidents.
- Compliance with regulatory requirements: Meeting industry-specific regulations like GDPR, HIPAA, and PCI-DSS is crucial for avoiding penalties and maintaining a positive reputation.
- Enhanced customer trust and brand reputation: Demonstrating a commitment to data security builds trust with customers and strengthens brand reputation.
- Reduced legal and financial risks: Preventing data breaches and complying with regulations reduces the likelihood of costly lawsuits and financial penalties.
- Better data governance and control: A well-defined security framework improves data governance and provides greater control over sensitive information.
- Support for privacy-by-design principles: Integrating security from the outset aligns with privacy-by-design principles and fosters a culture of data protection.
However, implementing robust security measures also presents some challenges:
- Increased complexity in system design and operations: Implementing and managing security features can add complexity to system architecture and operational processes.
- Potential performance impact from encryption overhead: Encryption and decryption processes can introduce performance overhead, potentially impacting application speed.
- Higher implementation and maintenance costs: Investing in security tools, training, and personnel can be expensive.
- May limit data accessibility for legitimate use cases: Strict security measures can sometimes hinder data accessibility for legitimate business purposes.
- Requires specialized security expertise: Implementing and managing complex security systems often requires specialized knowledge and skills.
Companies like Apple, Facebook, and numerous healthcare and financial institutions have successfully implemented robust data security and privacy controls. Apple leverages differential privacy for user data analytics, protecting individual privacy while still gathering valuable insights. Facebook employs secure multi-party computation for advertising insights, allowing collaborative data analysis without sharing raw data. Healthcare providers rely on HIPAA-compliant data integration platforms, and financial institutions adhere to PCI-DSS standards for secure payment processing.
Learn more about Data Security and Privacy Controls This article provides insights into securing REST APIs using personal access tokens, which is a relevant concept for secure data integration.
Here are some actionable tips for implementing effective data security and privacy controls within your data integration best practices:
- Implement defense-in-depth security strategies: Layer multiple security measures to create a robust defense against various threats.
- Use strong encryption algorithms and regularly update keys: Employing robust encryption algorithms and regularly rotating keys minimizes the risk of data compromise.
- Apply the principle of least privilege for data access: Grant users only the minimum level of access required to perform their duties, limiting the potential damage from unauthorized access.
- Regularly audit and monitor data access patterns: Monitoring access patterns helps identify anomalies and potential security breaches.
- Implement data classification and handling policies: Classify data based on sensitivity and establish clear handling procedures to ensure appropriate protection.
- Stay updated with regulatory requirements and best practices: Data privacy regulations are constantly evolving, so staying informed is crucial for maintaining compliance.
Incorporating these data security and privacy controls into your data integration best practices is not just a good idea—it’s a necessity. By prioritizing security, organizations can protect sensitive data, build trust, and ensure the long-term success of their data integration initiatives. For teams using Jira and HubSpot, ensuring data security within these integrated systems is paramount for protecting customer data and maintaining compliance. Consider tools like IBM Security Guardium, Microsoft Azure Information Protection, AWS Key Management Service, Privacera Data Security Platform, and Immuta Data Security Platform to strengthen your security posture.
8. Scalable ETL/ELT Pipeline Architecture
A robust data integration strategy hinges on the ability to handle increasing data volumes and complexity. This is where a scalable ETL/ELT (Extract, Transform, Load/Extract, Load, Transform) pipeline architecture becomes crucial. This best practice emphasizes building a flexible and efficient data pipeline capable of accommodating the ever-growing demands of modern businesses. It leverages modular design, parallel processing, cloud-native architectures, and automated scaling to ensure your data integration processes remain efficient and cost-effective as your data needs evolve. This is especially critical for teams using tools like HubSpot and Jira, where seamless data flow is essential for optimized workflows and informed decision-making.
A scalable ETL/ELT pipeline operates by breaking down the data integration process into smaller, manageable components. Data is first extracted from various sources, like HubSpot CRM or Jira Software/Data Center. In an ETL approach, the data is transformed before loading into the target system. In ELT, the raw data is loaded first and then transformed within the target system. This choice depends on your specific needs and resources. Parallel processing distributes the workload across multiple computing resources, significantly accelerating the integration process. Automated scaling dynamically adjusts resources based on demand, ensuring optimal performance and cost efficiency. This allows your system to adapt to fluctuations in data volume, velocity, and variety without manual intervention.
Companies like Spotify, Airbnb, Netflix, and Uber have demonstrated the power of scalable ETL/ELT pipelines. Spotify, for instance, utilizes large-scale ETL pipelines to power its personalized music recommendations, processing massive datasets of user listening history and music metadata. Similarly, Airbnb leverages sophisticated data processing infrastructure for booking analytics, providing valuable insights into customer behavior and market trends. These examples highlight how a scalable approach is essential for handling the complex data integration demands of high-growth businesses. These are data integration best practices in action, enabling these companies to derive maximum value from their data.
For businesses leveraging HubSpot and Jira, a scalable data integration architecture is essential for achieving true CRM-issue sync. Imagine your sales team in HubSpot needing up-to-the-minute information from Jira on the status of a customer’s technical issue. A robust ETL/ELT pipeline facilitates this two-way data sync seamlessly, ensuring everyone has access to the most current information. This eliminates data silos and promotes better collaboration between teams.
Actionable Tips for Implementing a Scalable ETL/ELT Pipeline:
- Design for horizontal scaling from the outset: Plan for your pipeline to grow horizontally by adding more computing resources rather than vertically scaling individual machines. This ensures flexibility and cost-effectiveness.
- Implement data partitioning: Divide your data into smaller, manageable chunks for parallel processing. This dramatically reduces processing time and improves efficiency.
- Embrace containerization: Utilize containerization technologies like Docker and Kubernetes for efficient resource management and simplified deployment.
- Monitor and optimize: Continuously monitor pipeline performance, identify bottlenecks, and optimize resource allocation for peak efficiency. Tools like Apache Airflow can be invaluable for managing and monitoring complex pipelines.
- Robust testing and staging: Implement comprehensive testing and staging environments to validate changes and prevent issues before deploying to production.
Pros and Cons of Scalable ETL/ELT:
Pros:
- Handles large volumes of data efficiently
- Cost-effective scaling based on demand
- Improved processing speed through parallelization
- Better resource utilization and optimization
- Flexibility to adapt to changing requirements
- Reduced infrastructure management overhead
Cons:
- Complex architecture design and implementation
- Requires expertise in distributed systems
- Potential for increased costs with poor optimization
- Debugging and troubleshooting can be challenging
- Dependency on cloud provider services and pricing
Learn more about Scalable ETL/ELT Pipeline Architecture (Note: While this link isn’t directly related to ETL/ELT, it points towards cost optimization strategies which are relevant when considering cloud-based data pipelines).
By implementing a scalable ETL/ELT architecture, businesses can establish a future-proof data integration strategy capable of handling the ever-increasing demands of a data-driven world. This data integration best practice empowers organizations, including those utilizing HubSpot and Jira, to unlock the full potential of their data and drive informed decision-making across all departments. For teams managing Jira workflows and needing seamless integration with HubSpot data, understanding and implementing these best practices is key to optimizing operations and achieving customer success. Implementing these data integration best practices ensures that crucial data flows efficiently between HubSpot objects and Jira issues. This alignment helps support managers track customer issues, allows product teams to prioritize development based on HubSpot feedback, and empowers rev-ops leaders with a comprehensive view of the customer journey. This is a crucial aspect of any successful HubSpot integration and Jira integration strategy.
8 Best Practices Comparison Guide
| Best Practice | Implementation Complexity 🔄 | Resource Requirements ⚡ | Expected Outcomes 📊 | Ideal Use Cases 💡 | Key Advantages ⭐ |
|---|---|---|---|---|---|
| Data Quality Management and Validation | High complexity; requires multi-system setup | High initial investment; ongoing maintenance | Reliable, accurate, consistent data; regulatory compliance | Businesses needing data accuracy and auditability | Improves decision-making; reduces errors; ensures compliance |
| Incremental Data Loading and CDC | Complex setup; requires robust tracking | Efficient resource use; minimal source impact | Faster syncs; near real-time updates; cost reduction | Large datasets with frequent changes; real-time analytics | Reduces processing time and bandwidth; scalable |
| API-First Integration Architecture | Significant upfront design and versioning | Moderate; depends on API ecosystem scale | Flexible, scalable integrations; secure data exchange | Microservices; third-party integrations; evolving systems | High flexibility; better security; easier maintenance |
| Real-Time Streaming Data Integration | High complexity; needs specialized skills | High infrastructure and operational cost | Immediate insights and low-latency processing | Fraud detection; IoT monitoring; real-time personalization | Enables faster decision-making; reduces data staleness |
| Data Lineage and Metadata Management | Considerable initial setup; maintenance needed | Moderate; depends on tool integration | Transparent data flow; better governance and compliance | Regulated industries; complex data environments | Enhances compliance; simplifies troubleshooting |
| Error Handling and Data Recovery Strategies | Moderate to high; requires thorough testing | Additional infrastructure and monitoring | Increased uptime; faster recovery from failures | Mission-critical systems; distributed architectures | Improves reliability; reduces data loss |
| Data Security and Privacy Controls | High complexity; security expertise required | High; encryption and monitoring overhead | Protected sensitive data; regulatory compliance | Data-sensitive sectors like finance, healthcare | Protects data; builds trust; ensures compliance |
| Scalable ETL/ELT Pipeline Architecture | Complex distributed system design | High resource use but auto-scalable | Efficient large-scale data processing; cost-effective scaling | Big data analytics; cloud-native environments | Handles large volumes; flexible and cost-efficient |
Streamlining Success: Data Integration Best Practices with resolution Reichert Network Solutions GmbH
Mastering data integration best practices is crucial for any business seeking to harness the full potential of its data. Throughout this article, we’ve explored essential strategies, from data quality management and validation to scalable ETL/ELT pipeline architecture, including incremental loading, change data capture, and real-time streaming. We’ve also highlighted the importance of API-first integration, data lineage, robust error handling, and stringent security measures. By implementing these data integration best practices, organizations like yours – with teams relying on both Jira and HubSpot – can break down data silos, improve collaboration between sales, marketing, support, and product teams, and gain a 360-degree view of the customer journey, leading to better decision-making and increased efficiency.
The key takeaway here is that effective data integration isn’t just about moving data; it’s about creating a connected ecosystem where information flows seamlessly, enabling accurate reporting, automated workflows, and ultimately, better business outcomes. Whether you’re a Jira administrator, DevOps manager, or a member of the sales, marketing, customer support, or product team, understanding and implementing these concepts can significantly impact your team’s performance and contribute to overall business success. Imagine a world where your HubSpot CRM and Jira instance work in perfect harmony, automatically syncing key information, saving your teams countless hours of manual data entry, and providing invaluable insights. This is the power of effective data integration.
Ready to experience the benefits of streamlined data integration between your HubSpot and Jira instances? Resolution Reichert Network Solutions GmbH empowers you to put these best practices into action with HubSpot for Jira, a powerful integration solution that connects your CRM and issue tracking system for seamless data synchronization. Try HubSpot for Jira free today and discover how it can transform your data management and propel your business forward. Resolution Reichert Network Solutions GmbH
