

Taming the Data Beast: Why Validation Matters for HubSpot & Jira Users
This listicle reveals eight essential data validation techniques to improve data quality and streamline workflows between your HubSpot and Jira instances. Learn how techniques like regular expression validation, schema validation, and database constraints can enhance data accuracy, consistency, and reliability. Clean data empowers better decision-making, reporting, and ultimately, customer satisfaction. Stop data discrepancies from hindering your team's productivity and explore these techniques for a more robust, integrated workflow.
1. Regular Expression Validation
Regular Expression Validation (Regex) is a powerful data validation technique that uses pattern matching to check if data conforms to specific rules. Think of it as a highly specialized search function, but instead of finding words, it finds patterns within strings. This allows you to define the exact format you expect data to follow – like an email address, a phone number, or even a complex password – and verify whether the input meets those criteria. This technique is crucial for maintaining data integrity, especially in integrated systems like HubSpot and Jira, where consistent data formats are essential for smooth operation.

Regex empowers your teams – from Jira administrators and DevOps managers to sales and marketing teams using HubSpot, customer support agents, product managers, and data analysts – by providing a precise and efficient way to validate text-based data. By ensuring data accuracy at the input stage, you prevent downstream issues caused by malformed data, improving reporting accuracy and overall system reliability. This is particularly relevant for maintaining data consistency between Jira and HubSpot. Accurate, validated data flowing seamlessly between these platforms empowers better decision-making across the organization.
Features and Benefits:
- Pattern-based Validation: Regex uses a specialized syntax to define patterns, enabling extremely granular control over acceptable data formats.
- Complex Validation Made Easy: Concise expressions can encapsulate intricate validation rules, reducing the need for verbose, error-prone manual checks.
- Wide Range of Applications: Validate everything from simple text fields to complex structures like emails, URLs, phone numbers, postal codes, and more.
- Language Agnostic: Implement Regex in virtually any programming language or platform, ensuring consistency across your tech stack.
- Improved Data Quality: By enforcing specific character sequences and lengths, Regex prevents invalid data from entering your system, leading to cleaner, more reliable data.
Pros:
- Highly Flexible and Powerful: Provides unmatched flexibility for text pattern validation.
- Efficient String Validation: Extremely efficient for verifying formatted strings, minimizing processing overhead.
- Reduced Code Complexity: Simplifies complex validation logic into concise expressions, making code easier to read and maintain.
- Wide Range of Scenarios: Handles diverse validation needs, from simple to complex.
- Platform and Language Independent: Works across different platforms and programming languages.
Cons:
- Steep Learning Curve: The specialized syntax can be challenging to learn initially.
- Maintainability Challenges: Complex patterns require thorough documentation to ensure readability and ease of maintenance.
- Potential Performance Issues: Very complex patterns can impact performance if not carefully optimized.
- Security Risks: Incorrectly implemented patterns can introduce security vulnerabilities.
- Limited to String Validation: Not suitable for semantic validation or data type checking.
Examples of Regex in Action:
- Email Validation:
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$ - Phone Number Validation:
^\+?[1-9]\d{1,14}$ - Password Strength Validation: Enforce minimum length, special characters, etc.
- Credit Card Number Format Validation: Ensure compliance with card number formats.
- Web Form Validation: Widely used in web applications like Facebook, Google, and e-commerce sites for real-time data validation.
Tips for Effective Regex Usage:
- Thorough Testing: Test your patterns with a wide range of inputs, including edge cases and potential invalid data.
- Comprehensive Documentation: Clearly document complex patterns to explain their purpose and logic, improving maintainability.
- Utilize Regex Testing Tools: Leverage online tools like Regex101 or RegExr to debug and optimize your patterns.
- Modularize Complex Patterns: Break down complex patterns into smaller, more manageable components for improved readability and maintainability.
- Performance Considerations: Be mindful of potential performance implications for highly complex patterns. Consider alternative approaches if performance becomes a bottleneck.
- Combine with Other Validation Techniques: For sensitive data, combine Regex with other validation methods for a more robust approach.
Why Regex Deserves its Place on the List:
Regular expression validation is a cornerstone of effective data validation techniques. Its flexibility, power, and broad applicability make it an indispensable tool for any team working with structured data. By incorporating Regex into your data validation strategy, you can significantly enhance data quality, prevent errors, and streamline data processing, ultimately improving the reliability and efficiency of your systems, including your crucial HubSpot and Jira integrations. Properly implemented regex can drastically reduce the incidence of bad data propagating between your CRM and issue tracking systems, keeping your revenue operations, support, and product teams working with consistent and accurate information. This improves reporting, forecasting, and ultimately, customer satisfaction.
2. Schema Validation: Ensuring Data Integrity in Your HubSpot and Jira Integration
Schema validation is a powerful data validation technique that leverages a structured approach to define and enforce data quality. It uses a schema – a formal description of your data structure – as a blueprint. This schema specifies the expected format, data types (like text, numbers, dates), constraints (e.g., minimum/maximum values, required fields), and relationships between different data elements. The validation process then compares incoming data against this schema to ensure it conforms to the defined structure before it's processed or stored. This technique is crucial for maintaining data integrity, particularly when integrating systems like HubSpot and Jira.

Schema validation acts as a gatekeeper, ensuring that only data meeting your predefined criteria enters your systems. It's like having a detailed checklist for every piece of information, guaranteeing consistency and reliability. This is especially important for teams working across HubSpot and Jira, where data accuracy is paramount for efficient workflows and reliable reporting. Imagine a sales team in HubSpot needing to create Jira tickets based on deal stages. Schema validation can ensure that the necessary information, such as deal size, contact details, and product type, is correctly formatted and present before a ticket is created, eliminating errors and streamlining the process.
For Jira administrators and DevOps managers, schema validation provides a robust mechanism for controlling the data flowing into Jira. This is essential for maintaining the integrity of issue tracking and project management workflows. Sales and marketing teams using HubSpot benefit from cleaner data, allowing for more targeted campaigns and accurate reporting. Customer support and service agents can rely on consistent information when resolving customer issues. Product and project management teams can track progress effectively based on reliable data. Data analysts and reporting specialists can draw meaningful insights from validated datasets, free from inconsistencies and errors.
Features and Benefits:
- Declarative definition: Describe your data structure and constraints in a clear and concise manner, making it easy to understand and maintain.
- Complex data structures: Supports validation of simple types as well as complex nested structures, catering to diverse data needs.
- Built-in validation: Leverages schema-defined rules for automatic type validation and constraint enforcement, reducing manual effort.
- Relationship validation: Ensures data integrity by validating relationships between different data elements within a schema.
- Self-documenting: Schemas serve as clear documentation of your data requirements, facilitating communication and collaboration.
Pros:
- Clear data expectations: Provides a clear and documented understanding of the expected data format and constraints.
- Reduced validation code: Centralizes validation rules in schemas, minimizing the need for scattered and repetitive validation code.
- Automatic error reporting: Facilitates automatic generation of detailed error reports when data fails validation, making debugging easier.
- Complex validation scenarios: Supports complex validation rules and scenarios, including nested objects and conditional constraints.
- API contract enforcement: Ensures data integrity in API interactions by enforcing predefined data contracts.
Cons:
- Verbosity: Can be verbose for simple validation needs, potentially adding unnecessary complexity.
- Learning curve: May require learning schema-specific languages or formats (e.g., JSON Schema, XSD).
- Runtime overhead: Adds some runtime overhead for validation processing, especially for large data structures.
- Schema maintenance: Requires ongoing maintenance of schemas as data structures evolve, adding to the development workload.
Examples:
- REST APIs: JSON Schema validation for REST APIs ensures that requests and responses conform to expected formats. Companies like Stripe and Twilio use this for reliable API interactions.
- SOAP Web Services: XML Schema Definition (XSD) validates XML data exchanged in SOAP web services, promoting interoperability.
- GraphQL APIs: GraphQL schema validation in Facebook, GitHub, and Shopify APIs maintains data consistency and predictability.
- Databases: Database schema validation in PostgreSQL, MongoDB, and other databases ensures data integrity at the database level.
- Form Validation: Form validation in enterprise applications often uses schemas like Formik with Yup to ensure valid user input.
Tips for Effective Schema Validation:
- Model First: Start with a clear understanding of your data model before defining schemas.
- Version Control: Use schema versioning to manage changes over time and maintain backward compatibility.
- Generate Documentation: Automate documentation generation from schemas to keep technical documentation up-to-date.
- Code Generation: Consider generating code from schemas to ensure type safety and minimize coding errors.
- Combine with Runtime Validation: For critical systems, combine schema validation with runtime checks for added security.
- Use Standards: Utilize existing schema standards like JSON Schema and OpenAPI whenever possible for interoperability and wider adoption.
By implementing schema validation as part of your data validation techniques, you can ensure that your data remains consistent, reliable, and ready for analysis, whether you're managing sales leads in HubSpot or tracking software development in Jira. Using a tool like the HubSpot for Jira integration can facilitate this process by automatically validating data synced between the two platforms, streamlining workflows and ensuring data integrity across your teams.
3. Cross-Field Validation
Cross-field validation, also known as interdependent validation, is a crucial data validation technique that goes beyond checking individual fields in isolation. It verifies data integrity by examining the relationships and dependencies between multiple fields. This approach ensures logical consistency across related data elements and enforces complex business rules, ultimately leading to higher quality data within your HubSpot CRM and Jira instances. This technique is particularly valuable for teams using HubSpot and Jira, where data integrity is paramount for accurate reporting, effective automation, and seamless workflows. Imagine a scenario where a discount code is entered in HubSpot, but the corresponding Jira issue doesn't reflect the adjusted price. This discrepancy can lead to revenue leakage and customer dissatisfaction. Cross-field validation prevents such issues by ensuring data consistency across both platforms.
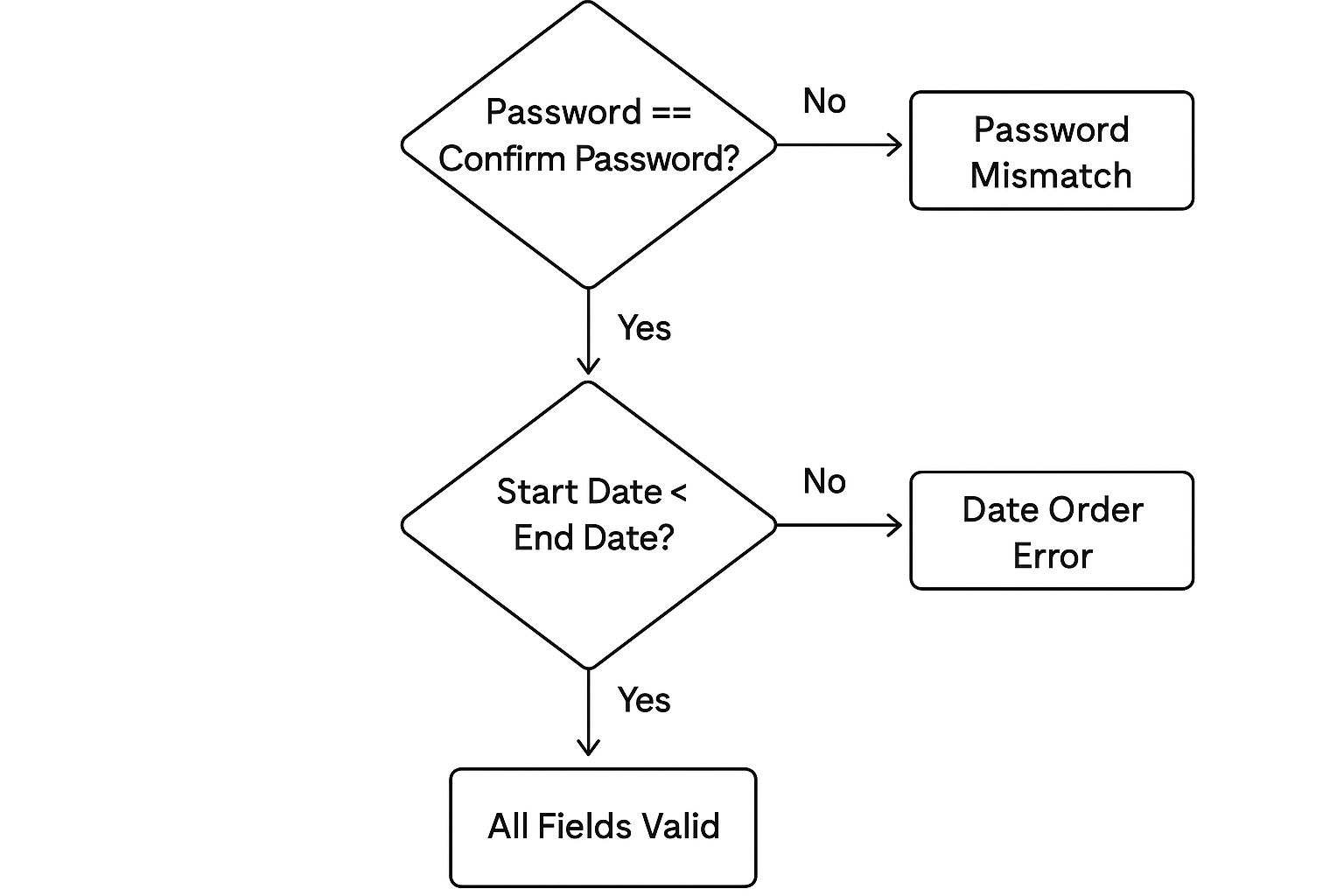
The infographic above visualizes a decision tree for implementing cross-field validation. It starts by identifying interdependent fields and then branches out based on whether the relationship is valid. Invalid relationships trigger specific error messages and prevent submission, guiding the user to correct the data. This ensures data accuracy before it enters your systems.
This data validation technique is essential for ensuring data accuracy and consistency between your CRM and issue tracking systems. By catching logical inconsistencies early, you can avoid downstream issues that affect reporting, automation, and ultimately, customer satisfaction.
For example, ensuring that a "Deal Stage" update in HubSpot correctly triggers a corresponding status change in a linked Jira issue relies on cross-field validation. Without it, your teams might be working with outdated or mismatched information. Features of cross-field validation include validating relationships between multiple data fields, enforcing business rules and logical constraints, supporting conditional validation requirements, and ensuring data consistency across related fields. These features enable the implementation of even complex validation workflows. This is particularly relevant for RevOps leaders, support managers, and product teams working with data that spans both HubSpot and Jira.
Pros:
- Catches logical errors: Identifies inconsistencies that single-field validation misses.
- Enforces business rules: Effectively implements complex business logic and constraints.
- Improves data quality: Ensures consistency and reduces downstream errors.
- Sophisticated UX: Enables conditional validation for a better user experience.
Cons:
- Increased complexity: Requires more intricate implementation than single-field validation.
- Custom code: Often necessitates custom code beyond standard validators.
- Testing challenges: Can be difficult to test all possible combinations thoroughly.
- User-friendly errors: Crafting clear error messages can be challenging.
Examples of Cross-Field Validation in HubSpot and Jira:
- Password Confirmation: Ensuring the password and password confirmation fields match.
- Date Ranges: Validating that the start date is before the end date in project timelines.
- Conditional Discounts: Applying discounts based on specific customer segments or product bundles in HubSpot, then reflecting the correct price in the linked Jira issue.
- Dependent Dropdowns: Selecting a country in HubSpot dynamically updates the available states/regions in both HubSpot and a corresponding Jira issue field.
Tips for Effective Cross-Field Validation:
- Clear Error Messages: Explain the relationship violation clearly to guide the user. Example: “Start date cannot be after the end date.”
- Validation Framework: Utilize a framework that supports cross-field rules. Consider leveraging the validation capabilities within the HubSpot for Jira app to simplify this process.
- Separate Logic: Decouple business logic from UI validation code for better maintainability.
- Comprehensive Testing: Test all possible combinations of interdependent fields.
- Real-Time Feedback: Provide immediate validation feedback to the user whenever possible.
- Clear Documentation: Document cross-field dependencies clearly in your specifications.
Popularized By: Hibernate Validator, React Hook Form, Angular, Spring Framework, Formik.
Decision Tree Example:
Let's say you're using HubSpot to manage deals and Jira to track the related development work. You want to ensure that when a deal reaches the "Closed Won" stage in HubSpot, the corresponding Jira issue automatically transitions to the "Done" status.
Decision Criteria:
-
Is the HubSpot deal stage "Closed Won"?
- Yes: Proceed to the next step.
- No: No action needed.
-
Does a linked Jira issue exist?
- Yes: Transition the Jira issue to "Done".
- No: Log an error or create a new Jira issue automatically (depending on your workflow).
This is just one example. By leveraging tools like the HubSpot for Jira app, you can easily configure and automate these cross-field validations, ensuring data consistency and reducing manual effort. The two-way field sync, automatic ticket creation, and contact/company panel features within the app greatly facilitate such implementations. For instance, a support manager could configure the integration so that when a customer's priority level is updated in HubSpot, the priority of the corresponding Jira issue is automatically adjusted as well. This streamlines workflows and prevents discrepancies between the two systems.
Cross-field validation earns its spot on the list of essential data validation techniques because it addresses the complexities of real-world business rules and data relationships. While it requires more upfront effort to implement, the long-term benefits in terms of data quality, reduced errors, and improved workflow efficiency are significant. Try HubSpot for Jira free to see how it can simplify your data validation processes.
4. Database Constraints: A Crucial Data Validation Technique
Database constraints are rules implemented at the database level to guarantee data integrity and consistency. These rules, defined within the database schema, automatically validate data during insert, update, and delete operations. This acts as a powerful last line of defense against data corruption, ensuring data validity regardless of the application or process interacting with it. This is especially critical for data validation techniques employed by teams working across platforms like HubSpot and Jira, where consistent data is paramount for accurate reporting, automation, and decision-making.

Database constraints form a cornerstone of robust data validation techniques. They provide a centralized, automated validation layer that operates independently of the application logic. This ensures data quality at the source, simplifying application development and maintenance. By enforcing these rules directly in the database, you avoid potential inconsistencies arising from different applications applying varying validation rules or bypassing validation altogether. This makes database constraints a vital component for any team, particularly those utilizing HubSpot and Jira, seeking reliable data validation techniques.
Several types of constraints are available to enforce various data integrity rules:
- NOT NULL: Ensures a column cannot contain NULL values.
- UNIQUE: Guarantees that all values in a column are unique.
- CHECK: Specifies a condition that each row must satisfy.
- PRIMARY KEY: Uniquely identifies each row in a table (a combination of NOT NULL and UNIQUE).
- FOREIGN KEY: Establishes a link between columns in two tables, ensuring referential integrity.
- Triggers: Enable the execution of custom validation logic in response to data modification events, offering a way to implement more sophisticated data validation techniques.
This rich set of constraint types provides flexibility in enforcing diverse data validation rules tailored to your specific needs.
Pros of Using Database Constraints:
- Ensured Data Integrity at the Storage Level: Data integrity is guaranteed regardless of how applications interact with the database.
- Centralized Validation Rules: Simplifies management and ensures consistency across all applications.
- Prevention of Invalid Data: Acts as a final safeguard against data corruption.
- Improved Performance: Often more efficient than application-level validation.
- Reduced Data Cleanup: Minimizes the need for manual data correction.
- Self-Documenting: Constraints are part of the database schema, providing built-in documentation.
Cons of Using Database Constraints:
- Less Flexible: Changing validation rules requires schema alterations.
- Generic Error Messages: Default error messages may not be user-friendly.
- Limited Expressiveness: Can be difficult to implement very complex business rules.
- Increased Complexity in Development and Testing: Introducing database constraints can complicate these processes.
Examples of Database Constraints in Action:
- E-commerce platforms: FOREIGN KEY constraints ensure product-category relationships are maintained correctly. This is invaluable for accurate reporting and inventory management.
- Healthcare Systems: UNIQUE constraints enforce the uniqueness of patient identifiers, preventing duplicate records and ensuring accurate patient data.
- Financial Institutions: CHECK constraints verify account balances remain positive, preventing overdrafts and maintaining financial integrity.
Tips for Effective Use of Database Constraints:
- Meaningful Naming: Use descriptive names to easily identify constraints in error messages.
- Strategic Balance: Find the right balance between database and application-level validation based on the criticality of the data.
- Transactions: Use database transactions to manage multiple related constraints atomically.
- Thorough Documentation: Document database constraints in both the schema and application code.
- Performance Considerations: Be mindful of the performance implications of complex constraints.
- Custom Error Handling: Implement custom error handling to translate database errors into user-friendly messages.
Database constraints are a powerful data validation technique that ensures data integrity and consistency at the core of your data storage. By leveraging the features and understanding the considerations outlined above, organizations can build robust data validation systems, especially valuable for teams working across HubSpot and Jira, where consistent data is vital for effective collaboration and decision-making. This approach allows your teams to maintain accurate, consistent, and reliable data, fostering trust in your data and supporting effective business operations. By adopting this robust data validation technique, you can streamline workflows and focus on key business objectives, confident in the quality and integrity of your data.
5. Type-Based Validation
Type-based validation is a crucial data validation technique that ensures your data conforms to the expected data types and formats. For teams working with HubSpot and Jira, maintaining data integrity is paramount, and type-based validation plays a key role in achieving this. This technique leverages strong typing systems or type checking to validate that each data element matches its intended type, whether it's a string, number, boolean, or more complex custom type. This approach can prevent frustrating errors stemming from type mismatches and improve the overall quality of your data. Imagine trying to perform calculations on a text field representing a number – chaos ensues! Type-based validation prevents this.
For example, if a HubSpot field is designated as a "number" and intended to store ages, type-based validation would reject an input like "twenty-five" and instead require "25". This validation can happen either statically during compile time (before the code runs) or dynamically at runtime (while the code is executing), giving you flexibility depending on your needs and the programming environment. This not only catches errors early in the development process but also prevents unexpected behavior in production.
Benefits for HubSpot and Jira Users:
Type-based validation offers several specific advantages for teams using HubSpot and Jira:
- Improved Data Integrity: By ensuring data types are consistent between HubSpot and Jira, you can trust the accuracy of your reports, analyses, and automated processes. This prevents issues arising from type mismatches during data synchronization.
- Enhanced Automation Reliability: Type-based validation safeguards your automated workflows. When you know your data types are correct, you can build reliable automations in both HubSpot and Jira, confident that your processes won't be disrupted by type-related errors.
- Streamlined Data Synchronization: The HubSpot for Jira app leverages data validation techniques, including type-based validation, to facilitate smooth, two-way data synchronization. This ensures that data transferred between the two platforms maintains its integrity, preventing inconsistencies and errors.
Features of Type-Based Validation:
- Validation against Predefined Types: Checks data against common types like integers, strings, booleans, dates, etc.
- Type Constraints: Supports additional constraints within types, such as numeric ranges (e.g., age must be between 0 and 120) or string formats (e.g., email addresses).
- Static and Dynamic Implementation: Offers flexibility by enabling both compile-time and runtime validation.
- Support for Complex Types: Can validate custom types and data structures relevant to your business.
Pros and Cons of Type-Based Validation:
Pros:
- Early Error Detection: Identifies type mismatches early in the development cycle, reducing debugging time.
- Improved Code Quality: Promotes clear and predictable code, making it easier to maintain and understand.
- Enhanced IDE Support: Enables better autocompletion and code navigation within development environments.
- Self-Documenting Code: Type definitions serve as documentation, clarifying the expected data types.
Cons:
- Increased Verbosity: Can add extra code, especially in statically-typed languages.
- Limited Scope: Primarily focuses on type conformance, not broader semantic validation (e.g., is the age reasonable?).
- Potential for Circumvention: Can be bypassed in weakly-typed languages.
Examples in Practice:
- TypeScript: Use TypeScript's static typing to define the expected data types for HubSpot and Jira fields, catching errors before runtime.
- Python with
mypy: Utilize type hints in Python and themypylibrary to perform static type checking on your data integration scripts. - Java: Leverage Java's strong typing system to enforce type correctness within your custom integrations or extensions.
Tips for Effective Type-Based Validation:
- Define Custom Types: Create custom types for domain-specific data within your HubSpot and Jira integration.
- Leverage Generics: Use generics to enforce type safety within collections and data structures.
- Combine with Runtime Validation: For critical applications, supplement type-based validation with runtime checks for complete data integrity.
- Clear Error Messages: Provide informative error messages that guide developers to fix type-related issues quickly.
Why Type-Based Validation Matters:
Type-based validation is essential for ensuring the reliability and consistency of your data, especially when integrating different systems like HubSpot and Jira. By ensuring data conforms to expected types, you can prevent errors, improve code quality, and build robust integrations that empower your teams to work more effectively. HubSpot for Jira inherently incorporates data validation techniques, including type validation, as part of its robust data synchronization process, contributing to a more seamless and dependable integration. This ultimately ensures data integrity across your sales, marketing, support, and product teams, improving collaboration and efficiency.
6. Input Sanitization
Input Sanitization is a crucial data validation technique that protects systems by actively modifying input data to neutralize potentially harmful content before it reaches validation or processing stages. Unlike validation, which simply accepts or rejects data, sanitization transforms the input to make it safe while preserving its intended meaning. This proactive approach is essential for robust data security practices and is especially critical for web applications, APIs, and other systems exposed to external data sources. Protecting sensitive information is paramount in today's digital landscape. Implementing robust data security practices, such as input sanitization, helps prevent vulnerabilities and safeguards data integrity. (Source: 23 04 2025 Datensicherheit Unternehmen from Deeken.Technology GmbH)
For teams working across platforms like Jira and HubSpot, maintaining data integrity is paramount. Input sanitization plays a key role in ensuring that data flowing between these systems remains consistent, reliable, and free from potentially harmful elements. Imagine a scenario where user-submitted data in HubSpot, containing malicious code, inadvertently syncs with Jira. Without proper sanitization, this could compromise the integrity of your Jira instance. Input sanitization, as a data validation technique, acts as the first line of defense against such scenarios.
How Input Sanitization Works
Input sanitization works by identifying and neutralizing potentially dangerous characters or patterns in the input data. This can involve several techniques, including:
- Escaping: Converting special characters like
<,>,", and'into their corresponding HTML entities (<,>,",') to prevent cross-site scripting (XSS) attacks. - Parameter Binding (Prepared Statements): In database interactions, this technique separates SQL code from user-provided data, preventing SQL injection vulnerabilities.
- Stripping Tags: Removing HTML tags entirely from input.
- Encoding: Converting data into a different format, such as URL encoding.
- Whitelisting/Blacklisting: Allowing or disallowing specific characters or patterns.
Benefits of Input Sanitization
Input sanitization provides several key advantages:
- Enhanced Security: Reduces vulnerabilities to common attacks like XSS and SQL injection.
- Data Integrity: Helps prevent data corruption caused by malformed input.
- Improved User Experience: Allows systems to handle minor data inconsistencies without outright rejection, leading to a smoother user experience.
- Defense in Depth: Adds an extra layer of security alongside other data validation techniques.
Pros and Cons of Input Sanitization
Pros:
- Reduces security vulnerabilities like XSS and SQL injection
- Can make marginally invalid data usable through transformation
- Adds defense-in-depth to validation strategies
- Helps protect against zero-day exploits in processing systems
- Can handle user errors without complete rejection of input
Cons:
- May alter user-provided data in unexpected ways
- Risk of over-sanitization leading to data loss
- Potential false sense of security if implemented poorly
- Performance overhead for complex sanitization rules
- Requires context-aware implementation based on data usage
Examples of Input Sanitization
- HTML Purifier (PHP): A robust library for sanitizing HTML content in web applications.
- DOMPurify (JavaScript): Client-side HTML sanitization library for securing user input in JavaScript applications.
- Prepared Statements: A standard technique for preventing SQL injection in database interactions.
- GitHub's Markdown Sanitization: Protects against malicious code execution within markdown content.
Tips for Effective Input Sanitization
- Context is Key: Apply sanitization based on the context where the data will be used (e.g., HTML context, SQL context).
- Sanitize Before Validation: Prevents attackers from bypassing validation checks with specially crafted input.
- Use Established Libraries: Leverage well-tested libraries like DOMPurify or HTML Purifier instead of building custom sanitizers.
- Data Type Specific Rules: Implement different sanitization rules for various data types (e.g., email addresses, phone numbers).
- Documentation and Testing: Document sanitization behaviors that might affect user experience and test with known attack patterns.
For data validation techniques to be truly effective in integrated environments like HubSpot and Jira, choosing the right tools is essential. A dedicated integration like HubSpot for Jira can help streamline these processes, ensuring that data is sanitized and validated effectively across both platforms. This not only enhances security but also improves data consistency and overall team efficiency. Using data validation techniques contributes significantly to the security and reliability of your data workflows. By incorporating this practice alongside other measures, you can bolster your overall data security posture and protect your systems from potential threats.
7. Domain-Specific Validation
Domain-Specific Validation is a crucial data validation technique that goes beyond basic checks like data type and format. It focuses on enforcing rules specific to a particular business domain, industry, or application context. This ensures that data not only adheres to technical specifications but also aligns with the semantic expectations and business rules of the specific domain. For teams working with interconnected systems like HubSpot and Jira, this level of validation is critical for maintaining data integrity and driving accurate insights. This validation technique deserves its place on this list because it tackles the complex, nuanced validation needs that generic approaches miss.
How it Works:
Domain-specific validation implements custom rules derived from domain knowledge, industry regulations, or internal business logic. It often involves a combination of multiple data validation techniques, including format checks, range checks, cross-field validation, and lookup against external reference data. This targeted approach ensures data accuracy and consistency within the specific context of the data's usage.
Features and Benefits:
- Implements rules specific to your business: Unlike generic validation, this technique tailors checks to your exact needs, be it validating medical codes, financial transactions, or legal documents.
- Enforces domain knowledge and business rules: It embeds domain expertise directly into your data validation process.
- Combines multiple validation techniques: This allows for handling complex, multi-layered validation scenarios.
- Validation against external data: Integrate with external APIs or databases for real-time validation against industry standards or reference data.
- Specialized algorithms: Employ custom algorithms for domain-specific calculations and validations.
Pros:
- Ensures business requirement compliance: Data is validated against actual business needs, not just generic formats.
- Reduces domain-specific errors and inconsistencies: Catches errors that generic validation would miss, improving overall data quality.
- Enforces regulatory compliance: Helps meet industry-specific regulations and avoid penalties.
- Improves data quality for domain-specific processing: Prepares data for accurate analysis and reporting.
- Reduces later data correction: Fewer errors mean less manual cleanup by domain experts.
Cons:
- Requires deep domain expertise: Implementing these rules effectively necessitates collaboration with domain experts.
- Often needs custom development: Off-the-shelf solutions may not cover all domain-specific needs.
- Difficult to maintain as domain rules evolve: Requires ongoing maintenance and updates as business rules change.
- Higher implementation costs than generic validation: The initial investment can be higher due to the customization required.
- Challenging to test comprehensively: Thorough testing is essential to ensure all domain-specific scenarios are covered.
Examples of Successful Implementation:
- Banking: Validating IBAN and SWIFT codes according to country-specific rules using a combination of regex and lookup tables.
- Healthcare: A HubSpot integration that validates patient data entered by sales against HIPAA compliance regulations before syncing to Jira for issue tracking.
- E-commerce: Validating product-specific attributes (e.g., dimensions, weight, material) based on product category using conditional logic within HubSpot workflows, ensuring consistent data before syncing to Jira for product development.
- Jira & HubSpot Integration: Imagine a support team using HubSpot for Jira. When a customer reports a bug, the HubSpot ticket contains a field for "Software Version". Domain-specific validation could check this version against a list of released versions maintained in Jira, preventing invalid versions from being logged and ensuring accurate bug reports. This minimizes back-and-forth with the customer and speeds up the resolution process.
Actionable Tips:
- Involve domain experts: Collaborate with them to define validation requirements accurately.
- Document domain rules: Clearly document all rules and their business justifications.
- Reusable components: Create reusable validation components for common domain-specific patterns.
- Consider regulatory changes: Stay up-to-date with regulatory changes and adapt validation rules accordingly.
- Versioning: Implement versioning for domain rules to track changes and maintain consistency.
- Testing with domain experts: Involve them in testing to ensure the validation logic covers all relevant scenarios.
Why Domain-Specific Validation is Essential for HubSpot and Jira Users:
For teams using HubSpot and Jira, maintaining data integrity across both platforms is crucial. Domain-specific validation ensures that the data flowing between these systems adheres to the unique business rules of each department. This prevents inaccurate data from propagating across the systems, leading to flawed reporting, inefficient workflows, and ultimately, poor business decisions. Using a tool like HubSpot for Jira allows for seamless integration and implementation of these crucial validation steps, ensuring data quality across both platforms. By leveraging the two-way sync capabilities of HubSpot for Jira, validation rules applied in one system can influence the other, maintaining consistent and high-quality data across all platforms.
When and Why to Use this Approach:
Domain-specific validation is essential when:
- Data accuracy is critical for business operations: For instance, in financial transactions or medical records.
- Regulatory compliance is mandatory: When dealing with sensitive data or operating in regulated industries.
- Complex business rules govern data integrity: When data needs to adhere to specific internal logic or workflows.
By implementing domain-specific validation, organizations can ensure that their data not only meets technical specifications but also aligns with their unique business needs and industry requirements. This contributes significantly to data quality, operational efficiency, and informed decision-making. For users of HubSpot and Jira, incorporating domain-specific validation within their integrated workflows, potentially through tools like HubSpot for Jira available on the Atlassian Marketplace, can drastically improve the reliability and actionability of their data.
8. Asynchronous Validation
Asynchronous validation is a powerful data validation technique that elevates user experience and enables sophisticated validation scenarios without compromising application responsiveness. Unlike synchronous validation, which blocks user interaction while checks are performed, asynchronous validation operates in the background, allowing users to continue interacting with the interface. This is particularly crucial for validations that involve external resources like databases, APIs, or complex computations, which can introduce latency. Asynchronous validation deserves its place in this list because it offers a significant improvement in how modern applications handle data input and validation, directly impacting customer satisfaction and operational efficiency for teams working with data-driven platforms like Jira and HubSpot.
How it Works
Asynchronous validation leverages asynchronous operations, often implemented using Promises, async/await (in JavaScript), or callbacks. When a user inputs data requiring validation, the application initiates a validation request without halting other processes. The application continues to function normally while the validation request is processed in the background. Upon completion, the validation results are returned and the interface is updated accordingly. This non-blocking nature significantly improves perceived performance and user satisfaction.
Features and Benefits
- Non-blocking operations: Maintains interface responsiveness during validation.
- External service integration: Enables validation against databases, APIs, and other external sources.
- Debouncing and throttling: Reduces server load by limiting validation requests, especially useful for real-time input validation.
- Real-time feedback: Provides immediate feedback to users without freezing the interface.
- Complex validation workflows: Supports multi-step and dependent validations without blocking the main application thread.
- Efficient large data set handling: Validates large amounts of data without impacting application performance.
Pros and Cons
Pros:
- Improved user experience: Responsive interfaces lead to greater user satisfaction.
- Enhanced validation capabilities: Allows for more sophisticated validation against external data sources.
- Reduced server load: Throttling and debouncing optimizes resource utilization.
- Support for complex workflows: Enables intricate validation processes without compromising performance.
- Efficient data handling: Scales well for large data sets.
Cons:
- Increased implementation complexity: Requires careful handling of asynchronous operations and state management.
- Potential for race conditions: If not implemented correctly, race conditions can arise, leading to inconsistent data.
- UI state management: Requires handling of loading and validating states in the user interface.
- External service dependencies: Relies on the availability and reliability of external services.
Examples of Successful Implementation
Asynchronous validation is widely used across various platforms. Consider these practical examples that resonate with Jira administrators, DevOps managers, sales and marketing teams using HubSpot, and data analysts:
- Username Availability Checking: During user registration, social media platforms utilize asynchronous validation to instantly check if a chosen username is already taken.
- Address Verification: E-commerce platforms validate addresses against postal service APIs in real-time during checkout, ensuring accuracy and minimizing delivery issues. This is analogous to verifying data integrity between HubSpot CRM contacts and Jira issue details.
- Credit Card Validation: Payment gateways employ asynchronous validation to confirm credit card details without interrupting the purchase flow.
- Autocomplete with Validation: Google Maps utilizes asynchronous validation to provide real-time address suggestions and validation during address input. This streamlined experience mirrors how HubSpot for Jira enhances data entry efficiency within Jira issues.
- Tax Identification Number Verification: Financial applications use asynchronous validation to verify tax IDs against government databases, ensuring compliance without delaying transactions. This is relevant to ensuring data accuracy between financial systems and Jira projects tracking revenue.
Actionable Tips for Implementation
- Visual Feedback: Implement clear loading states in the UI to inform users that validation is in progress.
- Debouncing/Throttling: Utilize debouncing or throttling to minimize excessive API calls, particularly during real-time input validation.
- Caching: Cache validation results whenever possible to reduce network requests and improve performance. This is especially valuable when validating against external services.
- Timeout Handling: Implement timeout mechanisms for external validation services to prevent indefinite waiting periods and handle potential network issues.
- Fallback Validation: Consider implementing fallback validation mechanisms when external services are unavailable to ensure a degree of data integrity.
- UI Design: Design the UI to gracefully handle asynchronous feedback, displaying errors and success messages appropriately without disrupting the user flow.
When and Why to Use Asynchronous Validation
Asynchronous validation is ideal in situations where:
- External Services: Validation relies on external services like databases, APIs, or third-party providers.
- Complex Computations: Validation involves complex calculations or processing that can introduce latency.
- Real-time Feedback: Providing immediate user feedback is crucial for a positive user experience.
- Large Data Sets: Validation needs to be performed on large amounts of data without blocking the main application thread.
By using asynchronous validation techniques, teams relying on data integrity between Jira and HubSpot can improve the quality of their data and enhance their workflows. Integrating a solution like HubSpot for Jira can further streamline this process by automating data validation and ensuring data consistency across both platforms. This results in more efficient operations, better decision-making, and improved customer experiences. The benefits are particularly impactful for rev-ops leaders, support managers, and product teams who need reliable data to effectively manage customer relationships and projects. Consider exploring the Atlassian Marketplace for apps like HubSpot for Jira that leverage these validation techniques to optimize your data workflows.
Data Validation Techniques Comparison
| Technique | 🔄 Implementation Complexity | ⚡ Resource Requirements | ⭐ Expected Outcomes | 💡 Ideal Use Cases | 📊 Key Advantages |
|---|---|---|---|---|---|
| Regular Expression Validation | Medium to High: Requires pattern syntax knowledge | Low: Runs efficiently on most systems | High for string format accuracy | Form validation, input format checks (email, phone) | Flexible, powerful for text validation, language-agnostic |
| Schema Validation | Medium: Schema languages/formats to learn | Medium: Requires schema parsers | Very High: Enforces structure & constraints | API input validation, complex nested data | Clear data contracts, centralized rules, automatic error reporting |
| Cross-Field Validation | High: Custom logic needed for inter-field rules | Medium: Depends on complexity | High: Ensures logical consistency | Business rules, conditional fields (password match, date range) | Catches relational errors, enforces business logic across fields |
| Database Constraints | Medium: Defined in DB schema, some complexity | Low: Managed by DB engine | High: Data integrity at storage level | Data integrity enforcement, multi-access environments | Centralized, prevents invalid data regardless of app |
| Type-Based Validation | Low to Medium: Leveraging language type systems | Low: Mostly compile-time or runtime checks | Medium: Ensures correct data types | Statically or dynamically typed languages, API type enforcement | Early error detection, improves code quality and tooling |
| Input Sanitization | Medium: Context-aware processing needed | Medium to High: Processing overhead | Medium-High: Security and data safety | Web input security, preventing XSS/SQL injection | Protects against injection attacks, converts unsafe input safely |
| Domain-Specific Validation | High: Requires deep domain knowledge | Medium to High: Depends on domain logic | Very High: Aligns data with business rules | Industry-specific compliance, business-critical validation | Reduces domain errors, enforces regulatory and business constraints |
| Asynchronous Validation | High: Async handling and state management | Medium: Network and concurrency resources | High: Responsive validation with external data | External lookups, real-time user feedback | Non-blocking UI, supports complex external validations |
Unlocking HubSpot-Jira Synergy: Streamlined Workflows Through Data Validation
Throughout this article, we've explored a range of essential data validation techniques, from regular expression validation and schema validation to input sanitization and asynchronous validation. We've also seen how cross-field validation, database constraints, type-based validation, and domain-specific validation play a crucial role in maintaining data integrity and streamlining workflows. By mastering these data validation techniques, your teams can unlock the true potential of your data, minimizing errors, improving decision-making, and enhancing overall operational efficiency. Remember, clean data isn't just a nice-to-have; it's the foundation for accurate reporting, effective automation, and ultimately, customer success.
The most important takeaway here is that proactive implementation of these data validation techniques is key. Don’t wait for data inconsistencies to disrupt your operations. Start by identifying the most critical data points within your HubSpot and Jira instances and apply the most appropriate validation methods. Prioritize areas where errors could have the biggest impact, such as lead qualification, customer support ticket resolution, or product development workflows.
By prioritizing data quality, you're not just cleaning up your data; you're investing in better customer experiences, more efficient processes, and more informed business decisions. Implementing these data validation techniques empowers your teams to work smarter, not harder, by ensuring everyone is working with reliable, consistent information.
Streamline your data validation process and optimize your HubSpot-Jira workflows with resolution Reichert Network Solutions GmbH’s app. It provides powerful two-way data synchronization and automated validation, ensuring data integrity between your CRM and issue tracking system. Try HubSpot for Jira free today and experience the transformative power of clean, validated data: resolution Reichert Network Solutions GmbH
