

When things go sideways—and they always do—the last thing you want is a team running around in a panic. That’s where incident management procedures come in. Think of them less as a stuffy corporate document and more as a crisis playbook for your entire business. It’s a clear, agreed-upon set of actions that kicks in the moment an unexpected disruption hits.
This isn’t about reacting; it’s about responding with a plan. A good procedure turns chaos into a structured, predictable process, ensuring you can get back to normal operations without breaking a sweat (or the bank).
Why Your Business Needs a Crisis Playbook

Picture a fire department showing up to a five-alarm fire with no plan. No one knows who’s in charge, which hydrants to use, or how to coordinate rescues. It would be a disaster on top of a disaster. That’s exactly what it’s like for a business facing a major service outage, a data breach, or a critical system failure without formal incident management procedures.
These procedures aren’t just for the IT folks in the server room; they’re a strategic asset for the whole company. They bring order to the chaos, protecting everything from your revenue and customer trust to your hard-earned brand reputation.
The Real Cost of Being Unprepared
In a world where everything is connected, how fast you respond to a problem is everything. A slow or disorganized reaction can cause damage that lingers long after the immediate issue is fixed.
It typically takes organizations an average of 197 days to discover a breach and another 69 days to contain it. That’s a massive window of vulnerability. For more context, check out these insightful incident management statistics from Invgate.
A well-oiled plan slashes this timeline. It transforms a potential catastrophe into a managed, contained event. Everyone knows their role, from the support agent who first spots the problem to the engineer who ships the fix.
Core Goals of Incident Management Procedures
A solid incident management plan is about more than just putting out fires. It’s built around a few core goals that not only solve the immediate problem but also make your organization stronger and more resilient in the long run.
Here’s a quick breakdown of what these procedures are designed to accomplish.
| Objective | Description |
|---|---|
| Rapid Resolution | The number one goal is to get things back up and running. Minimizing downtime is crucial to limit the impact on your business and customers. |
| Clear Communication | Keeping everyone in the loop—both internally and externally—with timely, accurate updates is key to managing expectations and maintaining trust. |
| Protect Reputation | A professional and effective response during a crisis can actually strengthen customer loyalty and protect your brand’s image. |
| Continuous Improvement | Every incident is a learning opportunity. Analyzing what went wrong helps you find the root cause and make changes to prevent it from happening again. |
Ultimately, these objectives work together to create a system that doesn’t just react to problems but actively learns from them, making your entire operation more robust.
The Incident Response Lifecycle Explained
Solid incident management doesn’t just happen by accident; it follows a clear, predictable lifecycle. Think of it like how an emergency medical team responds to a crisis. They don’t just show up and start doing things at random. Instead, they have a rehearsed, step-by-step process that moves from assessing the situation to providing treatment and, finally, ensuring a full recovery.
This same structured approach is what turns a chaotic website crash into a manageable problem with a clear path forward.
Every single incident, whether it’s a tiny bug or a full-blown outage, moves through five distinct phases. Getting a handle on this lifecycle is the secret to building incident management procedures that are both tough and repeatable. It guarantees every action is deliberate and moves you one step closer to getting things back to normal.
This initial flow chart shows those first critical moments when an incident strikes, visualizing the seamless handoff from detection to stabilization.
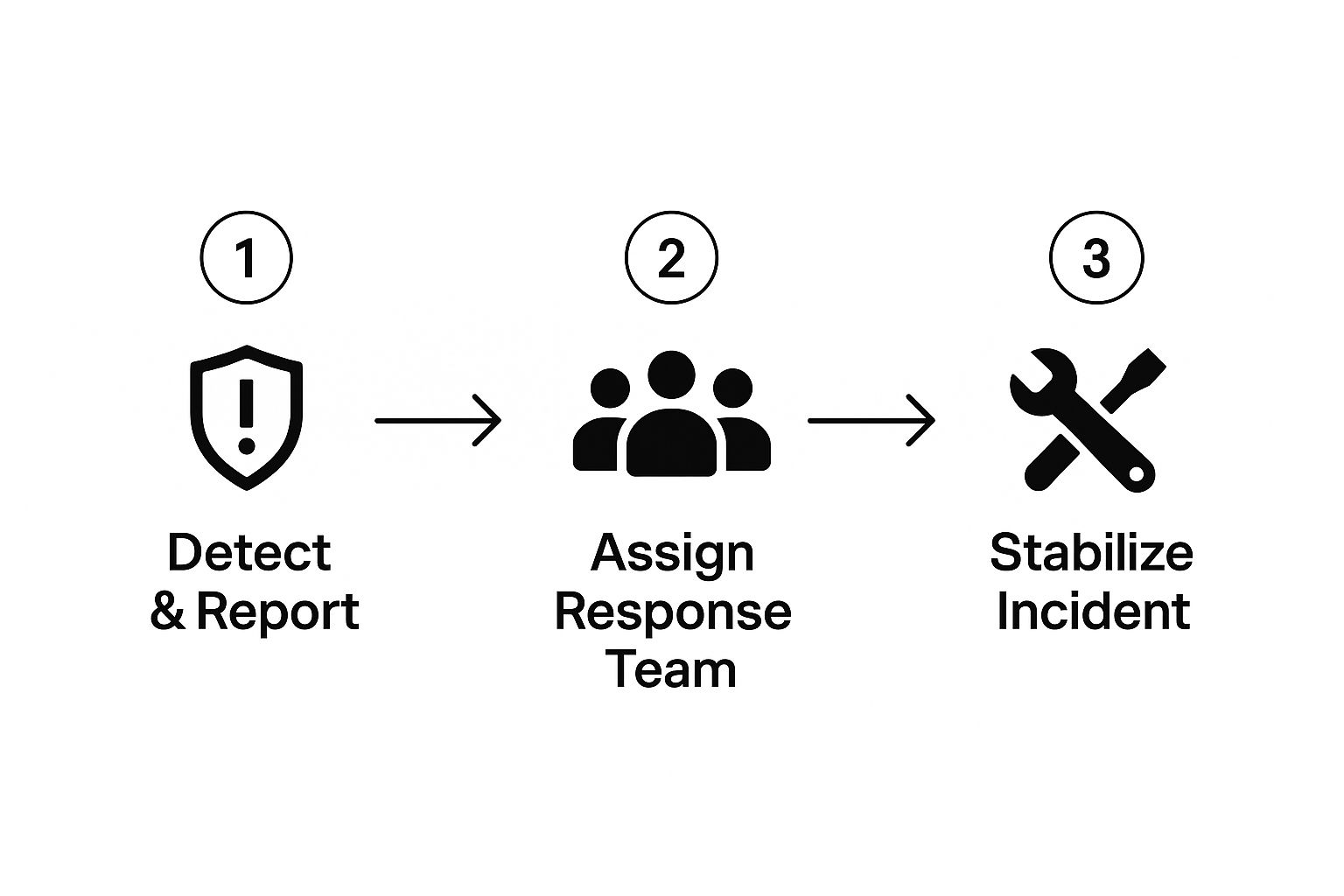
As you can see, a successful response kicks off with organized, sequential steps. This prevents the “all hands on deck” chaos and ensures the right people get pulled in right away.
The Five Phases of Incident Response
Let’s walk through the lifecycle using a classic, stomach-dropping scenario: your company’s e-commerce website suddenly goes down during a massive sales event. Here’s how a structured response would play out across the five phases.
-
Preparation
This is all the work you do before anything breaks. It’s about making sure your team is trained, communication channels are set up (like a dedicated Slack channel), and your tools are good to go. In our website crash scenario, good preparation means your monitoring tools were already configured to spot an outage and your on-call schedule is locked in. You know exactly who to call and have a clear chain of command. -
Identification
This phase kicks off the second an incident is detected. An automated alert fires off, or maybe a customer support agent flags that the site is down. The goal here is simple: confirm the incident is real, log it in a system like Jira, and figure out the initial blast radius. Is the whole site down, or just the payment gateway? This is where having a clear incident management process is absolutely crucial for gathering accurate details from the start. -
Containment
With the website down and sales grinding to a halt, your immediate job is to stop the bleeding. Containment isn’t about finding the root cause just yet; it’s about limiting the damage. This could mean something as simple as redirecting traffic to a static “We’ll be back soon!” page. You’re putting a temporary bandage on the wound to keep it from getting worse while you prep for the real fix.
The core principle of containment is damage control. You have to stop the incident from spreading and causing a domino effect across other connected systems. This step stabilizes the environment and gives your team the breathing room they desperately need for a proper investigation.
-
Eradication
Okay, the immediate crisis is contained. Now the team can switch gears to finding and stamping out the root cause for good. Your engineers might dig through logs and discover that a recent, faulty code deployment is the culprit behind the crash. Eradication means rolling back that bad code and running tests to be 100% sure the problem is gone. This is the permanent fix. -
Recovery and Post-Incident Review
With the faulty code gone, it’s time to bring everything back online. The website is restored, and your team keeps a close eye on it to ensure it’s stable. But you’re not done yet. The final, and arguably most important, step is the “post-mortem” or post-incident review. The team gets together to talk about what happened, why it happened, and how you can stop it from happening again. This is the learning loop that makes your organization stronger and more resilient over time.
Assembling Your Incident Response Team

Even the most well-documented incident management procedures are just words on a page without the right people to bring them to life. Building your incident response team is a lot like putting together a surgical team for a high-stakes operation. Every single member knows their exact role, and one person leads the charge, directing the whole effort.
This kind of structure is your best defense against the chaos and confusion that naturally crop up during a crisis. When people aren’t sure what they’re supposed to be doing, you get delays and crossed wires. With a clear chain of command, your team moves with purpose and speed. When an incident hits, that organized approach is your single greatest asset.
Core Roles and Responsibilities
Just like that surgical team has its lead surgeon, anesthesiologist, and nurses, your incident response team needs clearly defined roles. This makes sure every critical job gets done without people tripping over each other. While you might call them something different in your organization, most effective teams have a few key positions.
Here are the essential roles you’ll need to fill:
-
Incident Commander (IC): This is your leader and final decision-maker during an incident. The IC isn’t always the one writing code or rebooting servers; their job is to coordinate the entire response, manage resources, and make sure the team sticks to your incident management procedures. Think of them as the lead surgeon, guiding the operation from a strategic level.
-
Communications Lead: This person is the voice of the company, managing all communication both inside and outside the team. They’re responsible for drafting status updates for customers, keeping stakeholders in the loop, and ensuring everyone speaks with a single, unified message. Their work is absolutely crucial for maintaining customer trust and stopping misinformation in its tracks.
-
Technical Leads: These are your hands-on experts—the engineers, developers, and sysadmins who do the real work of diagnosing the problem and fixing it. You’ll likely have several Technical Leads, each a subject matter expert in a specific area like databases, networking, or the application itself.
Establishing a Clear Chain of Command
Having a well-defined hierarchy isn’t just a nice-to-have; it’s non-negotiable for a smooth incident response. It guarantees that decisions get made quickly and that everyone’s actions are coordinated instead of contradictory. Your chain of command should be simple and easy to understand, maybe even visualized in your documentation.
The main reason for a chain of command is to create clear paths for escalation. If a Technical Lead gets stuck, they know to go directly to the Incident Commander. This cuts out wasted time and makes sure the person with the authority to make the tough calls is always in the loop.
This structure is the backbone of your entire response. It’s what turns a group of talented individuals into a cohesive unit that can handle whatever crisis comes your way. Without these roles and a clear command structure, even the best incident management procedures will fall apart under pressure, costing you precious time and money.
Choosing Your Incident Management Toolkit
Modern incidents call for modern tools. It doesn’t matter how skilled your response team is; without the right technology backing them up, they’re fighting with one hand tied behind their back. Think of your toolkit as the central nervous system for your incident management procedures—it’s what connects your team, your data, and your workflows into a single, coordinated unit.
The right tech stack is what separates a disorganized scramble from a measured, real-time response. It becomes your command center, giving you the visibility and control you need to navigate a crisis successfully.
Key Tool Categories for Your Stack
A truly effective incident management toolkit isn’t just one piece of software. It’s a smart combination of integrated tools, with each one playing a specific, critical role. While the exact mix will depend on your business, most winning stacks include these core components:
-
Monitoring and Alerting Systems: These are your digital smoke detectors. Tools like Datadog or New Relic are always watching your systems for any sign of trouble. The moment they spot an anomaly—a server slowing down, a spike in errors—they automatically fire off an alert, which is the starting pistol for your entire response process.
-
Communication Hubs: When a crisis hits, clear and instant communication is everything. A dedicated platform like Slack or Microsoft Teams becomes the incident “war room.” This is where your team can coordinate, share updates, and make decisions without getting bogged down in endless email threads.
-
Incident Tracking Platforms: This is your official system of record. Platforms like Jira, PagerDuty, or Opsgenie are where you log the incident, assign ownership, track progress, and document every single action taken. This creates a bulletproof timeline for both accountability and post-incident reviews. And while we often think in terms of IT, this principle applies to physical emergencies, too. For example, the logic behind choosing emergency response tools for your business shares the same foundation of preparedness.
Bridging the Gap Between Teams
The real magic of a modern toolkit isn’t just in the tools themselves, but in how they talk to each other. A fragmented system where support, sales, and engineering operate in silos is a recipe for friction and painfully slow resolutions. This is where integrations become absolute game-changers.
The HubSpot for Jira integration, for instance, demolishes the wall that typically separates customer-facing teams from the developers.
When customer-reported issues in HubSpot can instantly become actionable engineering tickets in Jira, you eliminate dangerous information gaps. This ensures developers have the full customer context they need to diagnose and fix the problem faster.
Just look at how seamlessly customer information can be embedded right inside a Jira issue.
This direct link means engineers aren’t left chasing down critical details, and support agents get real-time status updates without ever leaving their CRM. It’s a perfect illustration of how the right tool integration supports your incident management procedures by aligning your teams and speeding up the entire lifecycle.
If you’re looking to formalize your processes, checking out some well-structured standard operating procedure templates can provide a fantastic starting point for building consistency into your response efforts.
Fortifying Your Procedures Against Cyber Threats

In the past, an “incident” usually meant something fairly straightforward. A server crashed. A pesky software bug knocked out a feature. But the game has changed completely. Today, many of your most critical incidents aren’t accidents—they’re calculated cyber attacks.
This shift means your incident management procedures can’t just be an IT troubleshooting guide anymore. They need to be a full-blown cyber defense plan. Treating a data breach or a ransomware attack like just another IT ticket is a recipe for disaster. These events are different because you’re up against a live, malicious actor who is actively working against you in real-time. Your response has to be faster and far more decisive.
Adapting to the Speed of Modern Attacks
The modern threat landscape moves at a blistering pace. Attackers aren’t lurking in the shadows for months anymore; they get in, grab what they want, and disappear with terrifying speed. Every single second counts.
We’re seeing a frightening acceleration in attack speed. For instance, data exfiltration now happens three times faster than it did in 2021. In fact, 25% of data breaches involve data being stolen in just five hours. Attackers are also hitting from multiple angles at once, with 70% of incidents involving three or more attack surfaces like endpoints, cloud environments, and networks. You can discover more insights about these attack trends to see why slow, manual responses just don’t cut it.
This reality means your procedures have to be built for pure speed. If you’re waiting for manual approvals or slowly trying to assemble a response team, you’re handing attackers the head start they need to do serious, lasting damage.
The core principle has to shift from reactive troubleshooting to proactive cyber defense. Your plan shouldn’t just be about fixing what broke; it must be about actively hunting, containing, and neutralizing an intelligent opponent inside your systems.
Building a Proactive Cyber Defense Posture
To stand a chance against these threats, your incident management procedures must be hardened with specific, cyber-focused elements. It’s all about building a defense that anticipates attacks, rather than just cleaning up the mess afterward.
Here’s how you can make your procedures more resilient:
-
Integrate Threat Intelligence: Don’t wait for an attack to hit you. Your procedures should include a process for constantly consuming threat intelligence feeds. This lets you proactively hunt for indicators of compromise (IOCs) and patch vulnerabilities before known threat actors can exploit them.
-
Develop Cyber-Specific Playbooks: Create pre-approved, step-by-step playbooks for common cyber attacks. Have a clear, well-drilled plan for a ransomware event, a phishing breach, or a denial-of-service attack. When an incident is flagged, the team can grab the right playbook and execute it immediately, no questions asked.
-
Assume Multi-Vector Attacks: Modern attackers rarely use just one door. Your response plan has to assume a breach could span cloud services, on-premise networks, and user endpoints all at once. Your investigation and containment efforts need to be coordinated across these different environments to be truly effective.
By embedding these cyber-centric strategies into your framework, you turn your procedures from a passive guide into an active defense mechanism. If you’re looking to formalize this process, our guide on incident management best practices offers a solid foundation for building out these more advanced capabilities. Taking this proactive stance is no longer optional—it’s essential for protecting your organization.
Even with the best incident management framework on paper, you’re bound to have questions when it’s time to put it all into practice. When you start formalizing your procedures, a few common concerns always seem to bubble up.
Getting ahead of these questions will help clarify the path forward and give your team confidence in the strategy you’re building. Think of this as your cheat sheet for navigating those practical hurdles. Answering these early on ensures your procedures are not just documented, but actually work when a real crisis hits.
What’s the Most Critical Part of a Response Plan?
While every piece of the incident lifecycle matters, most experts will point to one thing: clear, predefined roles and responsibilities. Without this, even the most brilliant technical plan will crumble under pressure.
It’s that simple. When people know exactly what their job is—and just as importantly, what it isn’t—the chaos melts away. This clarity prevents the “too many cooks in the kitchen” problem and stops critical tasks from falling through the cracks. It’s the bedrock that all other incident management procedures are built on.
How Often Should We Run Incident Drills?
Think of incident drills like fire drills for your digital world. They build the muscle memory your team needs to act on instinct when the pressure is on. The right frequency really depends on your company’s maturity and risk profile, but a great place to start is at least quarterly.
A scheduled drill is invaluable, but the real test comes from unannounced simulations. These surprise exercises reveal the true state of your readiness and expose gaps in your incident management procedures that planned drills might miss.
Remember, these practice runs aren’t about passing or failing. They’re about finding weak spots and continuously getting better, making sure your team is ready for the stress and complexity of a live event.
What Should a Post-Incident Review Include?
A post-incident review, often called a post-mortem, is your single most powerful learning tool. The goal is never to point fingers or assign blame, but to honestly look for systemic weaknesses that can be fixed.
Every solid review needs to have these components:
- A Detailed Timeline: A minute-by-minute log of what happened, from the first alert to the final resolution.
- Root Cause Analysis: Digging deep to find the fundamental trigger of the incident, not just the surface-level symptoms.
- Impact Assessment: What was the full damage? This includes the effect on customers, revenue, and your own internal teams.
- Actionable Follow-Ups: What specific, owner-assigned tasks will be completed to stop this from happening again?
This structured process turns a painful event into a powerful opportunity for growth, making your systems and your team stronger for the future.
Bridge the gap between your support and development teams with resolution Reichert Network Solutions GmbH. The HubSpot for Jira integration breaks down silos, providing your engineers with the full customer context they need directly in Jira, ensuring faster, more effective resolutions. Discover how to supercharge your incident response.
