
Let’s clear something up right away: the real difference between incident management and problem management boils down to their goals and timing. Incident management is reactive, all about getting a service back online fast after it goes down. Problem management is proactive, focused on digging deep to find the root cause of that disruption so it never, ever happens again.
The Firefighter vs. The Detective: An Introduction
Welcome to the ringside for a classic IT matchup: incident management versus problem management. On the surface, they look like partners fighting the same digital fires, but their playbooks couldn’t be more different.
Think of incident management as the emergency response team—the firefighters. Their job is singular: put out the fire and get services back online FAST. It’s all about containing the immediate damage.
Then, after the smoke clears, the problem management team arrives. They’re the detective squad, determined to figure out why the fire started in the first place and how to fireproof the building so it doesn’t happen again. This isn’t just a casual distinction; it’s formalized in frameworks like ITIL to keep teams from getting trapped in a constant cycle of firefighting.
This visual from Atlassian’s guide breaks down the core differences in focus and what each practice hopes to achieve.

As the image shows, incident management is all about speed and finding a quick workaround. Problem management, on the other hand, is about thorough investigation and implementing a permanent fix.
A Tale of Two Timelines
The true difference is in their operational timelines and what kicks them into gear. Incident management is all about the “now.” It’s triggered the second an alert goes off or a user reports a problem. From that moment, the entire process is a race against the clock.
The core philosophy of incident management is speed to recovery. The goal isn’t perfection; it’s restoring normalcy as quickly as possible to minimize business impact.
In contrast, problem management works on a much longer, more deliberate schedule. It usually kicks off after an incident has been resolved, using the data from that event to launch a deeper investigation. This separation is absolutely critical for building resilient, stable systems. To see this in action, check out our guide on essential incident management procedures.
To really nail down how they differ, let’s put their core functions side-by-side.
Incident vs. Problem Management At a Glance
The table below offers a high-level look at the core focus and goals of each discipline. It’s a simple way to see how the firefighter’s urgent, tactical approach differs from the detective’s methodical, strategic investigation.
| Aspect | Incident Management (The Firefighter) | Problem Management (The Detective) |
|---|---|---|
| Primary Goal | Restore service immediately | Eliminate the root cause |
| Focus | Reactive; speed and containment | Proactive; analysis and prevention |
| Trigger | A service disruption or outage | A recurring incident or an unknown cause |
| Key Metric | Mean Time to Resolve (MTTR) | Reduction in recurring incidents |
| Outcome | Service is back online (often with a workaround) | A permanent fix is implemented |
Ultimately, while incident management keeps the lights on day-to-day, it’s problem management that prevents the power grid from failing in the first place. Both are essential, but they solve very different business needs.
Comparing The Workflows From Outage to Analysis
To really get the difference between incident and problem management, you have to follow the action from the first alert all the way to the final analysis. Their day-to-day operations are as different as a sprint and a marathon. Each has its own pace, focus, and what it’s trying to achieve.
Let’s walk through how they each operate to see how they turn chaos into control.
The incident management workflow is all about speed—a high-stakes race to restore service immediately. It’s a purely reactive and tactical process that goes into overdrive the second a service is disrupted. The clock is always ticking.
Problem management, on the other hand, is a much more deliberate and investigative process. It only kicks in after the fire has been put out, shifting the focus from “fix it now” to “fix it for good.” This isn’t about speed; it’s about methodical, deep-dive analysis to make sure this doesn’t happen again.
The Incident Management Sprint
When an incident hits, the response is a flurry of coordinated activity designed for one thing: getting things back up and running fast. The entire process prioritizes speed, often using temporary workarounds just to get users back online. The main goal here is to crush the Mean Time to Resolve (MTTR), a make-or-break metric for any service desk.
This infographic breaks down the streamlined, three-step journey of incident management from the moment an issue is spotted to its final closure.
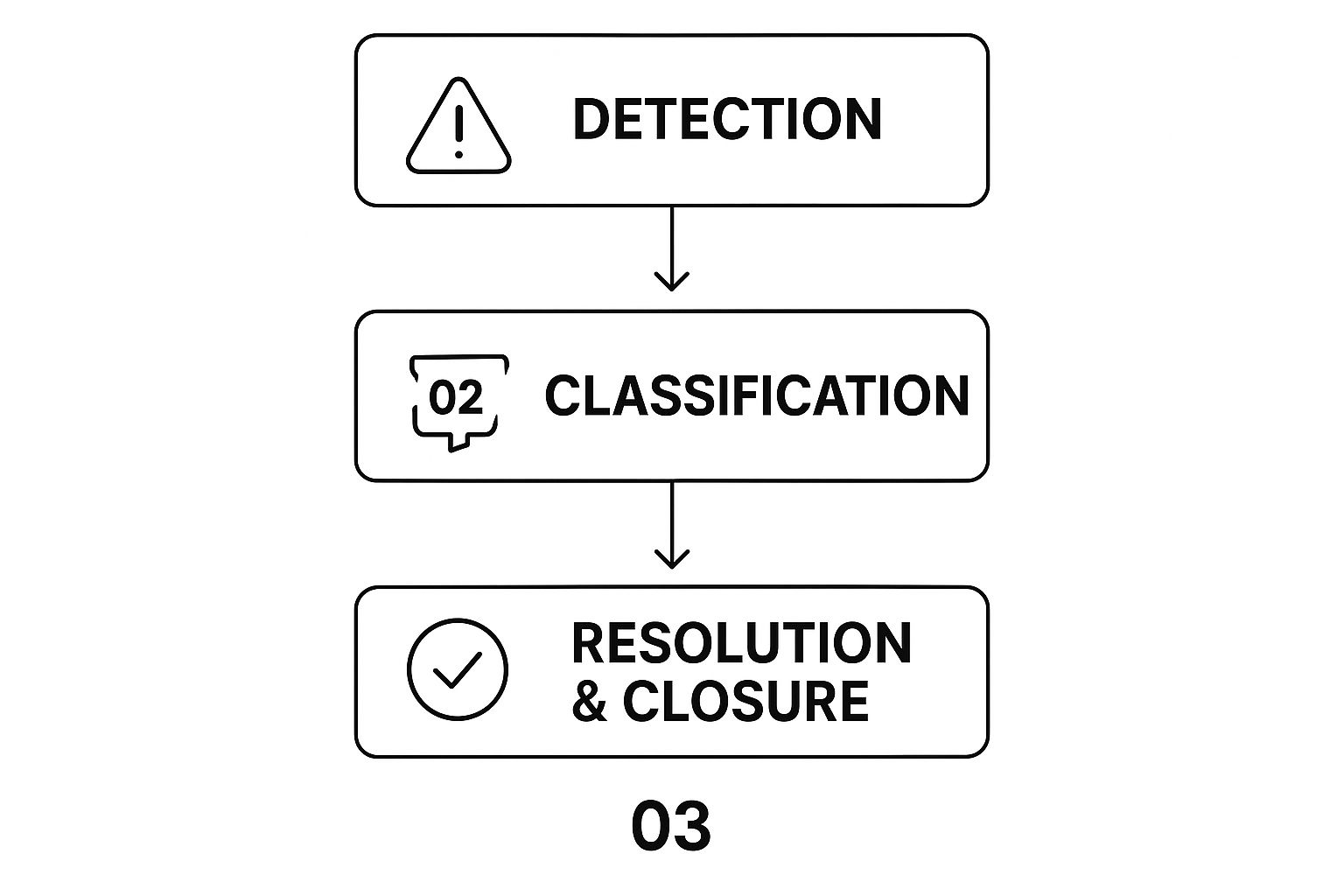
As you can see, incident management is a straight line. It’s a fast-paced sequence focused entirely on restoring service, with each step built to move the process forward as quickly as possible and keep business disruption to a minimum.
The Problem Management Investigation
Once an incident is closed—especially a major or recurring one—the problem management team takes over. Their workflow isn’t a sprint; it’s a full-blown investigation. They start by digging through data from past incidents to spot trends and hunt for underlying issues that aren’t immediately obvious.
The core idea behind problem management is that just because you resolved an incident doesn’t mean you’ve solved the real issue. You’ve only treated the symptom. Problem management is the cure.
This process has a few key stages that set it apart from a typical incident response:
- Problem Identification: This is about proactively digging into incident records, system logs, and user feedback. The goal is to find recurring issues or patterns that point to a deeper, hidden problem.
- Root Cause Analysis (RCA): This is where the real detective work happens. Teams use methods like the “5 Whys” or Fishbone Diagrams to get past the surface-level symptoms and uncover what’s truly causing the issue.
- Known Error Documentation: Once the root cause is confirmed and a workaround is figured out, it gets logged in a Known Error Database (KEDB). This is a huge help for the incident team, allowing them to resolve future occurrences much faster while a permanent fix is in the works.
- Permanent Change Implementation: The final piece of the puzzle. A change request is created to roll out a permanent fix, making sure the problem—and all the incidents it causes—are gone for good.
While these workflows are distinct, they’re also tightly connected. The quality of the data gathered during an incident directly feeds the effectiveness of the problem investigation that follows. Tracking the right service desk metrics is absolutely critical for both, creating the bridge that turns reactive firefighting into proactive prevention.
Measuring What Matters: Speed vs. Stability
So, how do you know if you’re winning the battle versus winning the war? In the world of incident management vs. problem management, you can’t use the same scorecard. Each practice is measured by a completely different set of Key Performance Indicators (KPIs) that reflect their unique goals: speed versus stability.
For incident management, success is all about the stopwatch. The metrics are designed to measure how fast and efficiently your team can stop the bleeding and restore service. It’s a direct reflection of your ability to minimize customer pain and business disruption in real-time.
Problem management, on the other hand, plays the long game. Its success isn’t measured in minutes or hours, but over months and quarters. The focus shifts from the speed of a single fix to the complete elimination of future disruptions.
Incident Management KPIs: The Need for Speed
When an outage strikes, every second counts. The key performance indicators for incident management all revolve around immediate action. Think Mean Time to Resolve (MTTR), which tracks the average time it takes to fix an issue from start to finish. With companies facing potential losses from $145,000 to $450,000 per hour of downtime, crushing this number is paramount.
Other vital metrics include:
- First Call Resolution (FCR): This measures the percentage of incidents resolved by the first point of contact, reflecting the efficiency and knowledge of your support team. A high FCR means users get back on track faster.
- Incident Volume by Category: This tracks where your incidents are coming from, helping to identify immediate hotspots that need attention. It’s your early warning system.
The philosophy behind incident management metrics is simple: How fast did we fix it? Every KPI is designed to shorten the gap between disruption and restoration, preserving business continuity.
These metrics provide a clear, immediate picture of your team’s reactive capabilities. Consistently improving them is crucial, and you can learn more about how to effectively measure team performance in our detailed guide.
Problem Management KPIs: The Pursuit of Stability
Problem management uses a completely different set of KPIs focused on long-term value and prevention. Success here means that incidents simply stop happening. The goal is to make the incident management team’s job easier by removing the source of their work.

Here, we’re looking at metrics that prove you’re getting ahead of the curve:
- Reduction in Recurring Incidents: This is the ultimate measure of success. It directly shows that underlying problems are being solved for good, not just patched up.
- Root Cause Identification Rate: This tracks how many problems have a confirmed root cause, proving the effectiveness of your investigative process. It’s not enough to fix something; you need to know why it broke.
- Number of Known Errors Documented: A growing Known Error Database (KEDB) shows that the team is successfully identifying issues and providing valuable workarounds, even before a permanent fix is in place.
This stark contrast in metrics really highlights the different value each practice delivers. One saves the business from immediate pain, while the other saves the business from future chaos.
Real-World Scenarios Where Each Process Shines
Let’s move from theory to the real world. The best way to grasp the critical relationship between incident and problem management is to see the handoff in action. These everyday situations show how one team’s reactive fix provides the perfect launchpad for another team’s proactive, permanent solution.
Imagine a huge e-commerce site in the middle of a Black Friday-style flash sale. Suddenly, the checkout system craters. Customers are stuck, unable to buy anything, and every second of downtime means thousands in lost sales. This is a classic Code Red scenario, a perfect job for the incident management team.
Their one and only mission? Stop the bleeding—fast. There’s no time to ponder why it all went wrong. They jump straight into their runbook, rerouting payment processing to a backup system and rebooting the application servers. Within minutes, the checkout is back online, and the sale is saved.
The Detective Takes the Case
Once the service is restored, the incident is closed, but the story is far from over. Now, it’s problem management’s turn to step up. Their work starts right where the incident team’s ended. Treating the crash like a crime scene, they dive into server logs, performance data, and the incident report itself.
After some digging, they uncover the real culprit: a subtle memory leak in a new shipping calculator plugin. It was a sneaky bug that only reared its head under the extreme load of the flash sale. The incident team’s reboot was a necessary band-aid, but the problem team develops a permanent patch to plug that memory leak for good.
This handoff is where the magic really happens. You’ll find that many incident management best practices emphasize creating detailed reports, which provide the essential clues for the problem investigation that follows.
The core difference is crystal clear: Incident management saved the day’s revenue. Problem management saved the company from having the exact same crisis during the next big sale.
The Nagging Monday Morning Slowdown
Now, let’s look at a different, more chronic issue. Every single Monday morning, without fail, employees complain that the internal CRM is painfully slow and keeps timing out. The incident team knows the drill: they get the tickets, reboot the server, and the problem vanishes… until next Monday.
This cycle of repeated, temporary fixes is a textbook trigger for problem management. The team looks past the simple server reboot and starts investigating what happens over the weekend. They soon discover a poorly optimized sales report query that runs every Sunday night, hogging system resources and leaving the server sluggish for Monday’s traffic.
- Incident Response: Reboot the server to give immediate relief to frustrated employees.
- Problem Solution: Rewrite and optimize the database query so it runs efficiently without crippling system performance.
In both scenarios, the incident team handled the immediate, visible symptom. But it was the problem management team that delivered the long-term cure, preventing future chaos and turning a reactive firefighting cycle into a stable, predictable operation.
Uniting Your Teams for Continuous Improvement

When you stop pitting incident management against problem management and see them as a power duo, your entire IT operation changes. It’s no longer about just putting out fires. Instead, you build a virtuous cycle where one team’s output becomes the other’s input, shifting your organization from constant firefighting to proactive, long-term improvement.
This synergy goes far beyond just closing tickets faster. It’s about creating a smarter, more resilient operation. Incident data provides the breadcrumbs for problem investigations, which then lead to permanent fixes that stop future incidents before they even happen. The result? A dramatic drop in downtime and a real boost in team morale as people move from crisis mode to meaningful, high-impact work.
Creating a Seamless Handoff
For this to work, you absolutely need a smooth, formalized handoff between the two teams. When an incident is resolved—especially a major or recurring one—the process can’t just end there. There has to be a clear trigger that kicks off a problem investigation. Otherwise, valuable insights get lost in the rush to the next emergency.
This is where integrated tools like Jira Service Management are worth their weight in gold. They let you directly link a whole mess of incidents to a single, underlying problem record. This creates a crystal-clear audit trail and gives problem managers all the context they need in one spot, finally breaking down those frustrating information silos. Of course, good cross-functional team communication is the glue that holds this whole thing together.
The goal is to evolve IT from a reactive cost center into a proactive, value-driving business partner. This happens when the detective’s findings directly improve the firefighter’s tools and environment.
The Business Impact of an Integrated ITSM Strategy
The benefits of combining these processes aren’t just operational—they show up on the bottom line. When organizations track both incident and problem management KPIs, they see tangible results that get the attention of leadership.
This table highlights just how powerful an integrated approach can be, turning day-to-day IT activities into measurable business wins.
| Metric | Reported Improvement | Primary Driver |
|---|---|---|
| Repeat Incidents | Up to 30% Annual Decrease | Root cause analysis from problem management permanently fixes issues. |
| Customer Satisfaction | Up to 20% Increase | Increased service stability and reliability lead to fewer disruptions for users. |
| Time to Resolution | 15-25% Faster | Problem management identifies and provides known errors and workarounds. |
| Operational Costs | 10-15% Reduction | Fewer major incidents and less time spent on reactive firefighting. |
By uniting these teams, you’re not just improving efficiency; you’re cultivating a culture of continuous improvement. Every problem you solve for good makes the entire system stronger. This means fewer disruptions, happier customers, and an IT department that’s seen as a strategic partner in growing the business.
Choosing The Right Tools for The Job
A brilliant strategy is only as good as the tools you use to bring it to life. When it comes to the distinct worlds of incident management and problem management, picking the right service management platform is what empowers both your firefighters and your detectives. A unified tool is your best defense against critical information getting lost in translation between teams.
Think about a platform like Jira Service Management. It’s a great example of how specific features can be tailored to support each discipline. For incident management, it’s all about speed and communication. Your tool has to have on-call scheduling to get the right eyes on an issue instantly, automated escalation rules so nothing slips through the cracks, and deep integrations with communication channels like Slack or Microsoft Teams to keep everyone on the same page during a crisis.
This screenshot from Atlassian gives you a peek into the Jira Service Management interface, which is built to centralize both service requests and incidents.
You can see how the layout neatly separates different request types. This is huge for operations teams, as it lets them spot and prioritize incoming incidents for immediate action without getting bogged down.
Features for Proactive Problem Solving
Now, for problem management, the tool’s focus pivots from raw speed to analytical depth. Here, you’re looking for features that support a thorough investigation. This means things like robust root cause analysis (RCA) templates to guide the process, solid integration with a knowledge base for documenting known errors, and a clean handoff to your change management workflows.
The real magic of a modern ITSM tool is its ability to create a single source of truth. It lets you directly link a dozen different incidents to one underlying problem record, finally breaking down the silos that let recurring issues fester for months.
This linkage is everything. When your incident team sees that a new ticket is already tied to an ongoing problem investigation, they get instant access to workarounds. Even better, every new incident linked to that problem adds another piece of the puzzle for the problem management team, helping them build a stronger case for a permanent fix.
This isn’t just about teams working in parallel anymore. It’s about them working together, using the same data, to build a far more stable and reliable service environment.
Got a few lingering questions about the whole incident vs. problem management thing? You’re not alone. Let’s break down some of the common questions that come up when teams start trying to get a handle on both.
Can One Person Really Do Both Jobs?
In a small shop, yes, but it takes an incredible amount of discipline. You have to be able to mentally switch gears. When you’re in incident mode, it’s all about speed. When you’re in problem mode, it’s about being thorough and getting it right.
The only way this works is by using a tool to create separate “incident” and “problem” tickets. This creates a formal boundary, stopping that crucial root cause analysis from getting shoved to the back of the line every time a new fire starts.
When Does an Incident Turn Into a Problem?
An incident officially becomes a problem when you start seeing it again and again, or when the service is back up, but nobody has a clue why it broke. You’ve fixed the symptom, but the disease is still there.
A good rule of thumb is to create a formal problem record when:
- The same incident pops up more than once.
- A major incident happens, and the root cause isn’t immediately obvious.
- The workaround you’re using is expensive or a huge pain, making a deeper investigation worthwhile.
The biggest trap I see companies fall into is getting stuck in permanent “incident mode.” They become incredible firefighters but never actually find the time to do problem management. This leads straight to team burnout and systems that are constantly on the verge of breaking.
A solid ITSM strategy needs a real, top-down commitment to proactive problem-solving, even when the waters are calm. It’s the only way to break out of that reactive firefighting cycle and build something that’s genuinely stable.
Bridge the gap between your project planning and issue tracking. With resolution Reichert Network Solutions GmbH, you can embed live monday.com boards right inside your Jira issues. This keeps communication flowing and ensures your teams are always looking at the same real-time data. Explore the monday.com for Jira integration today and tear down the silos that are holding your projects back.
