
What You’re Really Getting Into With Jira Imports
Let’s be honest, Jira imports can be a real pain. I’ve talked to tons of teams about their migrations, from tiny projects to massive enterprise datasets, and I’ve seen it all. Some teams fly through importing 10,000+ issues in a few hours, while others get bogged down for days with simple formatting issues. The key takeaway? Preparation is everything.
One huge trap is thinking all CSV files are the same. Something as small as using a comma instead of a semicolon as a delimiter can cause a total disaster. I’ve personally seen teams lose days of work because of this. Similarly, special characters or Unicode text lurking in your data can completely halt the import process. These little details can corrupt your data or just make the whole thing fail. That’s why understanding Jira import quirks is so important.
Importing issues into Jira via CSV files has long been vital for migrating from other project management platforms. As of 2024, Jira lets you import data into several projects at once by adding columns for project names and keys. This is a lifesaver for large migrations. Want to learn more? Discover more insights on importing data from CSV files.
Another crucial piece is field mapping. It’s like translating languages – some words have direct equivalents, others need more careful interpretation. This is exactly how field mapping from your old system to Jira works. Picking the correct Jira field type is essential. Imagine mapping a date field to a text field – total chaos. Nailing the field mapping early on saves you a mountain of trouble later, preventing data loss and keeping your information clean throughout the import. By the way, you might find this interesting: Check out our guide on Jira resource management.
Finally, remember that some early decisions, like your CSV structure and field mapping, are basically set in stone. Making the wrong call here can sink your whole project. Invest time in upfront planning. These initial choices have a massive impact on the import’s success and the efficiency of your entire migration. Proper planning ensures a smoother transition and minimizes potential problems.
Preparing Data That Actually Works With Jira
Getting your data ready for a Jira import can seem like a chore, but it’s honestly the most crucial step. I can’t tell you how many times I’ve seen imports go sideways just because the source data wasn’t quite right. Think of it like baking a cake: bad ingredients equal a bad cake.
Date Formats and Special Characters: The Silent Killers
Date formats are a frequent offender. Jira is specific, and if your dates aren’t formatted the way it expects, things can go south fast. I once spent hours troubleshooting an import, only to discover the dates were dd/mm/yyyy instead of yyyy-mm-dd. Don’t repeat my mistake! Double-check what Jira needs and format your data accordingly. Special characters and Unicode text can also cause problems. My advice? Stick to plain text whenever possible.
CSV Structure: The Foundation of a Smooth Import
The structure of your CSV file is the foundation of your import. It’s the blueprint for how your data will fit into Jira. A messy CSV means messy results – missing fields, wrong data types, the whole nine yards. Make sure your column headers are exactly the same as the Jira field names. Sounds simple, but you’d be surprised how often this trips people up. Also, consider breaking down large datasets into smaller, more manageable chunks. This can help with performance and makes it easier to find and fix problems. If you’re considering Jira but exploring other options, you might find this comparison of Kanban Tasks as a Jira alternative helpful: Jira alternative.
Testing and Validation: Your Safety Net
Before you hit that import button, test your data! A small sample import can save you a world of pain. It lets you catch any remaining issues early, before they turn into major headaches. After the import, you might want to set up some automated workflows. This article might be helpful: Learn more in our article about Jira workflow automation. Think of a test run as a dress rehearsal. It’s a chance to smooth out any wrinkles before the big show. This will save you time and ensure a smooth and successful Jira import.
Field Mapping That Makes Sense (Finally)
Field mapping is where so many Jira imports go sideways, but trust me, it doesn’t have to be a headache. Think of it like putting together a puzzle. Some pieces fit perfectly, while others need a little… persuasion. Let’s talk about how to make your fields click smoothly into place.
Understanding Jira Field Types
The first key is understanding Jira field types. You have your basic text fields, number fields, and date fields. Then you have the more specialized ones like user pickers and version pickers. Knowing the purpose of each field is crucial. Trying to squeeze a paragraph of text into a single-line text field? Yeah, that’s not going to end well.
Let’s talk about some real-world examples. Imagine you’re importing customer feedback. Long-form comments belong in a multi-line text field, while a customer satisfaction rating (1-5) fits perfectly in a number field.
Handling Custom Fields and Data Relationships
Custom fields can be a little more… interesting. If your old system has a custom field with no direct match in Jira, you’ll need to think outside the box. Sometimes you can map it to a similar Jira field type. Other times, you might need to create a brand new custom field in Jira before you start the import. Don’t forget about data relationships. If your old issues have links to other issues, you’ll want to keep those connections intact. Losing those relationships can make your Jira data feel like a plate of spaghetti.
To give you a better idea, let’s look at a few common field mapping scenarios:
Before we dive in, I want to give you a handy guide to common field mapping scenarios. This table breaks down the most common situations you might encounter:
| Source Field Type | Jira Field Equivalent | Mapping Notes | Common Issues |
|---|---|---|---|
| Text (Short) | Single-line Text Field | Straightforward mapping | Exceeding character limits |
| Text (Long) | Multi-line Text Field | Good for descriptions, comments | None |
| Number (Integer) | Number Field | Ensure data format consistency | Decimal values might be truncated |
| Number (Decimal) | Number Field or Float Field | Choose the appropriate field type | Data loss if using Number Field for large decimals |
| Date | Date Picker | Format the date correctly in your CSV (yyyy-mm-dd) | Incorrect date formatting leading to import errors |
| User | User Picker | Map user names or email addresses. | Usernames not matching causing unassigned issues |
| Status | Status | Ensure status values are identical in both systems | Incorrect status mapping |
After reviewing this table, you should have a much clearer understanding of how to approach common field mapping challenges. Remember, consistency is key!
User Mapping: Aligning Your Teams
User mapping can be a tricky beast. Imagine your old system uses full names, but Jira needs usernames or email addresses. You have to map those names correctly, otherwise, issues might get assigned to the wrong people. I’ve seen this create chaos and delays firsthand, so double-check those mappings.
Handling Missing or Incomplete Data
Missing data? It happens. Sometimes fields in your old system are empty. Jira’s usually pretty good about handling this. However, if a required Jira field is missing, your import will likely crash and burn. You can either fill in the missing data in your source file or use default values during the import. I once had a huge dataset with tons of missing due dates. I set a default due date for all those issues, and it saved me hours of manual work. Seriously, use those defaults! They’re a lifesaver. These techniques will keep your Jira import headaches to a minimum and ensure a smooth data transfer.
Managing Large Imports Without Breaking Everything
Importing thousands of issues into Jira? Let’s talk about how to avoid a total system meltdown. Believe me, size does matter here. I’ve personally seen organizations successfully migrate anywhere from 5,000 to 50,000+ issues, and I’m here to share the secrets to a smooth migration.
Batching: Your Secret Weapon for Large Imports
Batching your Jira imports is absolutely crucial for keeping your data clean and your system healthy. It’s like moving house – you wouldn’t try to carry everything at once! You’d pack things up box by box. Similarly, splitting your import into smaller, more digestible batches makes the entire process significantly less stressful.
So, what’s the ideal batch size? Honestly, it varies. It depends on factors like the complexity of your data and the specifics of your Jira environment. Atlassian themselves recommend smaller chunks for optimal performance. From my experience, importing around 1,500 work items can take up to an hour, but your mileage may vary depending on your setup. My advice? Start small with a test batch. Then, gradually increase the size until you find the perfect balance for your system. More details can be found in the Atlassian documentation.
Maintaining Consistency and Tracking Progress
Consistency is paramount when importing in batches. Each batch needs to have the same structure and mapping. Imagine building with LEGOs where bricks from different sets don’t fit together – chaos! Keep a meticulous record of your progress. A simple spreadsheet has been my go-to tool for this. I use it to track completed batches, any errors encountered, and pending imports. This keeps me organized and prevents accidental duplicates.
Handling Dependencies and User Notifications
Dependencies between issues can be tricky with batched imports. For example, if issue A is blocked by issue B, and they’re in separate batches, make absolutely sure issue B is imported first. Also, think about user notifications. Jira can send an email for every change, and with a huge import, that’s a recipe for inbox overload. Consider temporarily disabling notifications or using a dedicated channel to avoid overwhelming your users.
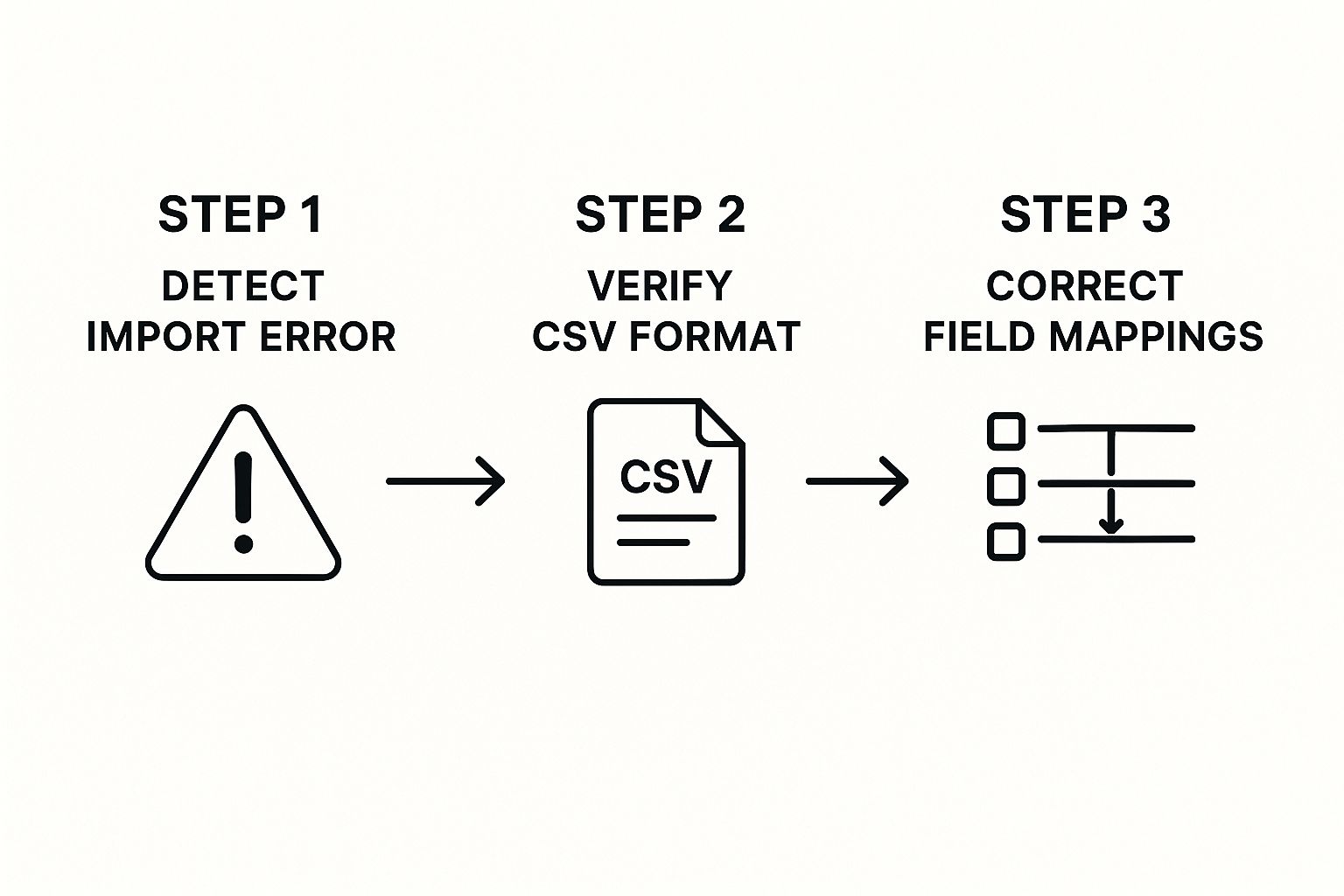
This infographic illustrates the troubleshooting process for Jira import issues. Notice how it emphasizes verifying the CSV format and correcting field mappings if an error pops up. These simple checks can save you a ton of time. Also, if you’re interested in capacity planning, this article is worth a read: Read also: Jira capacity planning.
Recovering from Errors and Monitoring Performance
So, what happens if an import goes sideways? Don’t freak out! Have a recovery plan. Regular backups are your best friend here. If a batch fails, restore your system to the previous state and try again. It’s also smart to monitor Jira’s performance during the import. Keep a close eye on resource usage, like CPU and memory. If things are getting overloaded, scale back your batch size or tweak some system settings.
Handling Data Conflicts Like a Pro
So, you’re getting ready to import issues into Jira Cloud. You’ve painstakingly prepped your CSV file, mapped all the fields, and you’re feeling pretty good. But wait! What happens when your shiny new data crashes head-on into the information already in Jira? This is where careful planning is crucial. I’ve seen firsthand how overlooking this step can turn a smooth migration into a total data disaster.
Understanding Conflict Resolution Approaches
Think of it like merging two busy highways – you need clear rules to avoid a massive pileup. When importing Jira issues, you have two main options: merging and overwriting. Merging gracefully combines your new data with the existing data, kind of like a careful zipper merge. Overwriting, on the other hand, completely replaces the existing data with your import data – a more aggressive approach, like changing lanes without looking.
The best choice really depends on what you’re trying to achieve. If you’re just updating existing issues with some fresh info, merging is probably your best bet. But if you’re migrating from a completely different system and want a clean slate in Jira, overwriting might make more sense. For example, I once helped a team migrate from Trello to Jira, and overwriting was essential for a fresh start.
One important consideration is data overwriting within Jira Cloud itself. When you’re importing from a CSV file, Jira gives you the option to overwrite existing data or merge it with existing issues. This flexibility can be incredibly useful when you’re consolidating data from various sources. Learn more about importing issues into Jira Cloud.
Backing Up Your Data: The Ultimate Safety Net
Before you even think about merging or overwriting, back up your Jira data. I can’t stress this enough. It’s your safety net, your insurance policy, your get-out-of-jail-free card. Trust me, you’ll thank yourself if something goes sideways during the import. There are tons of ways to back up Jira, from built-in tools to third-party apps. Pick the method that works best for you, and double-check that your backup is complete and accessible.
Handling Duplicates and Overlapping Data
Duplicate issues are another major pain point during imports. Imagine importing a ton of issues, only to discover that many are already lurking in your Jira instance. This can lead to a chaotic mess, especially if you rely on unique issue keys. I once saw this happen with a client, and it took us days to untangle the duplicates.
Fortunately, there are ways to tackle this. You can use Jira’s built-in duplicate detection features or explore third-party apps specifically designed for identifying and merging duplicate issues. Sometimes, you might even need to deactivate some users during the import process. You might be interested in: How to deactivate Jira users.
Preserving Configurations and User Assignments
Finally, don’t forget about user assignments. What if the usernames in your import data don’t match the usernames in your Jira instance? You’ll need a strategy to map these users correctly. This might involve creating new users or updating existing user profiles. I once spent hours manually mapping users during a migration – learn from my mistake and plan ahead!
Also, remember your custom Jira configurations. You want to make sure these settings are preserved during the import. This includes workflows, permissions, and any other customizations you’ve made. Taking these precautions will make your import smoother and keep your Jira instance organized.
Let’s talk about data conflict resolution strategies. Choosing the right strategy can save you a lot of time and headaches. Here’s a table summarizing some common approaches:
Data Conflict Resolution Strategies
| Conflict Type | Merge Strategy | Overwrite Strategy | Best For | Risk Level |
|---|---|---|---|---|
| New data for existing fields | Combine new and existing data | Replace existing data with new data | Updating existing issues | Low (with backups) |
| Conflicting data in same field | Append new data to existing data | Replace existing data with new data | Combining data from multiple sources | Medium |
| Duplicate issues | Merge duplicate issues | Overwrite existing issue with new data | Removing redundant issues | High |
| User mismatches | Map imported usernames to existing Jira users | Create new Jira users based on import data | Migrating users from another system | Medium |
This table highlights the key differences between merging and overwriting and gives you a sense of the risks involved. Remember, backing up your data is essential, especially when using the overwrite strategy.
By thinking through these considerations and taking proactive steps, you can transform your Jira import from a potential data minefield into a controlled and predictable process. This sets your team up for success and saves you from a world of pain down the road.
Fixing Problems When Imports Go Wrong
Let’s be honest, even when you think you’ve got your Jira import perfectly set up, things can still go sideways. So, let’s talk troubleshooting – how to fix those problems fast. I’ve picked up a few tricks over the years, and I’m happy to share what actually works.
Decoding Jira’s Error Messages
First things first: those Jira error messages. Sometimes they’re helpful, sometimes…cryptic. One you’ll see a lot is “Invalid field value.” Super helpful, right? Nope. This usually means you’ve got a data type mismatch – like trying to put text into a number field. Look closely at the row number and field name in the error. That’s your clue to find the bad data in your CSV file.
Another classic is the dreaded “User not found” message. This one usually means your user mapping is messed up. Double-check that usernames and email addresses in your CSV exactly match your Jira users. Trust me, even a tiny typo can cause this.
Identifying Root Causes and Implementing Fixes
Once you’ve figured out what the error message actually means, it’s detective time. You need to find the root cause. Is it a data formatting problem? Wrong field mapping? Corrupted data? I once spent hours on an import problem, only to discover a random semicolon hiding in my CSV. Infuriating!
After you’ve found the culprit, implement the fix. This might mean cleaning up your data, tweaking field mappings, or even restarting the import. This is why backups are so important. If things get really bad, you can always restore and try again. Speaking of helpful resources, check out our guide on Jira automation rules. Automation can be a lifesaver!
Handling Partial Imports and Corrupted Data
Partial imports are tricky. Some issues make it in, others don’t. This can create inconsistencies and mess with your project structure. You can try rolling back the partial import and starting fresh. Or, manually fix the problem issues and re-import the rest. Each situation is different, so choose what works best for you.
This screenshot from Atlassian Support shows Jira import settings. Look at the options for data conflicts – you can overwrite existing data or merge new data. This lets you control how the import interacts with your current Jira setup.
Corrupted data can stop your import dead in its tracks. This could be special characters, wrong data formats, or just bad data. Clean it up before you start importing. Text editors or spreadsheet software can help you find and fix those errors.
Preventing Problems Before They Happen
The best way to handle import problems? Prevent them! Here’s how:
-
Validate your data: Before you even think about importing, check your data thoroughly. Look for formatting errors, missing fields, and anything that looks off.
-
Test with a small sample: Do a small test import first. This helps you catch problems early, before you import everything.
-
Double-check your field mappings: Accuracy is key, especially for custom fields and user mappings.
-
Monitor the import process: Watch the import progress closely. If you see errors, fix them right away. Don’t wait until the whole thing is finished.
These tips will minimize problems and help ensure a smooth and successful Jira import. A little prep work goes a long way!
Your Import Success Roadmap
So, we’ve covered the ins and outs of importing issues into Jira. Now, let’s talk strategy. Think of this as your personalized game plan, based on everything we’ve discussed.
Prioritize Preparation
Data prep is king. I can’t stress this enough. It’s where everything begins. A clean, organized CSV file is like gold. Remember those tricky date formats and special characters? Nail them down now. And good communication is key. Knowing how to write bug reports that get fixed is a skill you’ll want in your toolbox.
Map Your Fields Strategically
Next up: field mapping. This is where you connect the dots between your source data and your Jira fields. Don’t be shy about creating new custom fields if you need them. Trust me, the time you spend here will save you headaches later. I’ve personally seen projects get held up for weeks because of messy field mapping. Learn from my mistakes!
Manage Large Imports Wisely
If you’re working with a large import, break it down into smaller batches. Start small, test it out, then gradually increase the batch size. This prevents system overload and makes troubleshooting a breeze. I once imported 20,000 issues this way without a single hiccup.
Handle Conflicts and Errors Gracefully
Data conflicts happen. It’s just the reality. Decide how you’ll handle them—merge or overwrite—before you begin. And back up your data. Always. It’s your safety net. Errors will pop up, too. Jira’s error messages can be confusing, I know. But a little detective work will usually get you to the root of the issue.
Celebrate Your Wins
Finally, celebrate! Jira imports can be tough, but with good preparation and patience, you can make it happen. A smooth, efficient migration is something to be proud of.
Looking for ways to improve your team’s workflow and manage absences? Check out the Out of Office Assistant for Jira Cloud. It might just be what your team needs to stay on track.
